
The NLSY97 uses rosters in various sections in which information is collected on a number of persons, schools, or employers. Rosters are an important part of the NLSY97 data set. These grids of information help researchers to analyze data in an efficient and accurate way. However, the structure and use of rosters may be somewhat confusing, so it is vital that researchers understand how they are constructed. After describing the construction and use of rosters, the following pages list the variable names, titles, and reference numbers for the various instrument rosters used during the round 1-9 interviews. These lists are intended to aid researchers in identifying the types of information organized in each roster and to better follow the flow of information through the interview.
Click below to view roster details and examples:
A roster may be thought of as a list: for example, a list of household members, a list of employers, or a list of children. A respondent with two children will have data on the first two lines of the child list, or child roster. A respondent with four employers will have information on the first four lines of the employer roster. In addition to the name of the person or item (which is not released to the public), the roster contains other basic information, such as the age, race, and labor force status of household members or the start date and stop date for each employer.
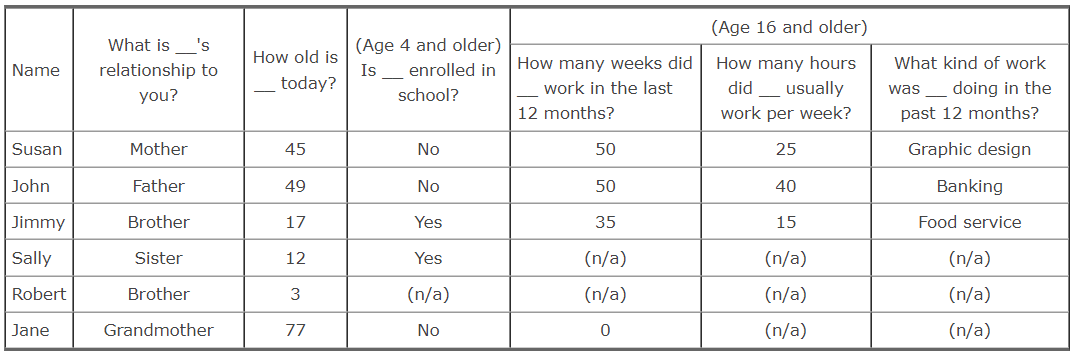
In the paper-and-pencil interviews (PAPI) of older NLS cohorts, the questionnaires included a chart or grid listing this type of information, like the one shown in Figure 1 below. For example, in the household roster grid, each household member's name was entered in a separate row. The interviewer asked the respondent for each member's date of birth, enrollment status, employment status, etc., filling in the answers in the appropriate column. This completed household roster contained all the pertinent information about household residents, and researchers could easily use the variables based on this roster to examine characteristics of household members.
Figure 1. Sample PAPI roster grid
What are the names of all family members who are living in your home?
When the NLS surveys changed to computer-assisted personal interviewing (CAPI), rosters became a very important way of organizing information during the interview. Instead of using an actual grid, however, CAPI questionnaires include a series of questions that gather the same types of information that would have been included in the grid in a paper-and-pencil interview. The computer then moves the answers to these questions into a grid, creating a roster from the information.
After the roster is created, it can be used to guide subsequent portions of the interview. For example, during the interview the NLSY97 questionnaire gathers the names, dates of attendance, and level of school (secondary school or college) for each of the respondent's schools and organizes them into a roster. The rest of the school section then asks questions about the first school on the roster, followed by questions about the second school, then the third, and so on. The information about the level of the school determines whether the respondent is asked questions that apply to high school or college.
The information from the roster is also presented in the data set as an organized list of data, so that these variables are easy for researchers to access. To the user, the school roster appears as a consolidated block of variables that contains key information such as dates of enrollment, an identification number for the school, and variables indicating the type (private or public) and level (junior high, high school, college) of the school. For example, the variables in the round 2 school roster are listed in Figure 2, along with their reference numbers. Thus, rosters are a way of organizing information both for researchers and for the actual interview so that questions are asked in a logical manner.
|
Question Name |
Variable Title |
Reference Numbers |
|---|---|---|
| NEWSCHOOL_PERIODS.xx | Number of Times R Enrolled in School xx | R24605.-R24610. |
| NEWSCHOOL_START1.xx | Month/Year R Start 1st Enrollment in School xx | R24611.00-R24616.01 |
| NEWSCHOOL_START2.xx | Month/Year R Start 2nd Enrollment in School xx | R24617.00-R24620.01 |
| NEWSCHOOL_START3.xx | Month/Year R Start 3rd Enrollment in School xx | R24621.00-R24621.01 |
| NEWSCHOOL_STOP1.xx | Month/Year R End 1st Enrollment in School xx | R24622.00-R24627.01 |
| NEWSCHOOL_STOP2.xx | Month/Year R End 2nd Enrollment in School xx | R24628.00-R24631.01 |
| NEWSCHOOL_STOP3.xx | Month/Year R End 3rd Enrollment in School xx | R24632.00-R24632.01 |
| NEWSCHOOL_SCHCODE.xx | School Code Elementary, Middle, High, College | R24633.-R24638. |
| NEWSCHOOL_INTERVIEW.xx | Which Survey Round School xx Reported in | R24639.-R24644. |
| NEWSCHOOL_TYPE.xx | Type of School xx R has Attended | R24645.-R24650. |
| NEWSCHOOL_PUBID.xx | PUBID of School xx R has Attended | R24651.-R24656. |
This section includes the Creation and use of the employer roster example.
This section outlines the process used during the interview to create a roster. Rosters may include data from both previous interviews and the current interview. After the roster is created and sorted, it can be used to guide the rest of the interview. Figure 3 provides a pictorial overview of the creation of a roster.
Figure 3. How rosters are created
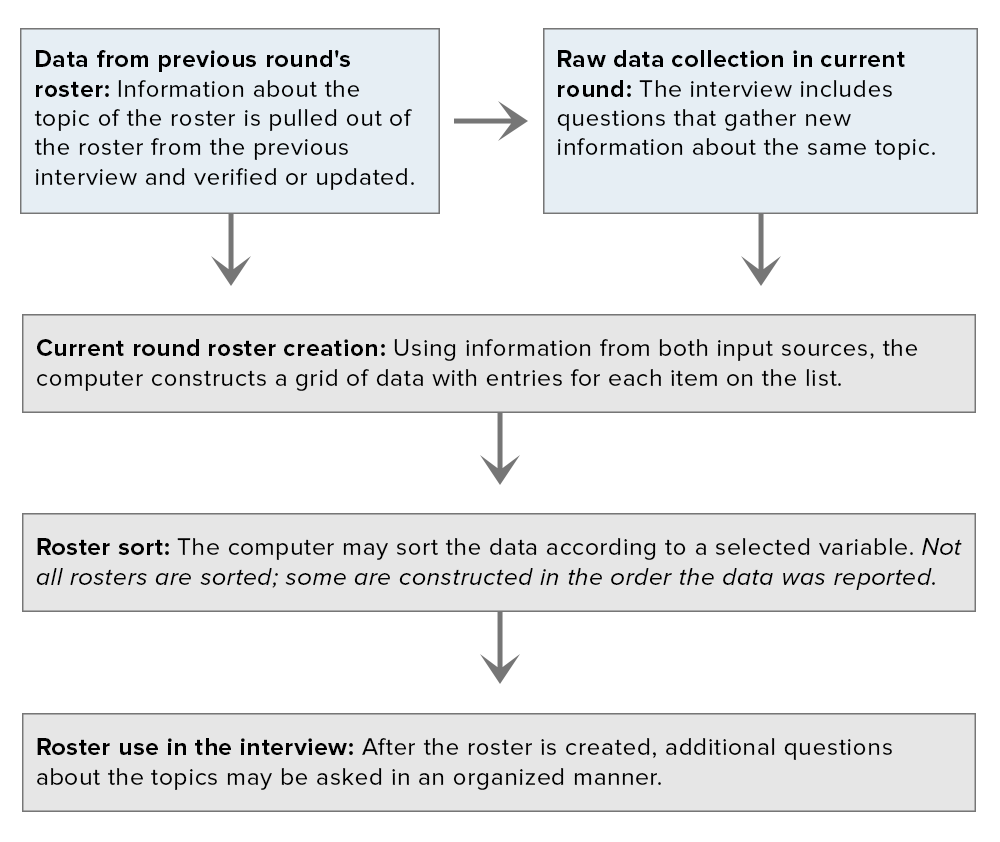
Click to enlarge Figure 3 | Read a text version of the Figure 3 flowchart
Data from previous interviews
As shown in the figure, creation of a roster for the current round often begins with information found in the roster from the previous round. The appropriate respondent-specific data are saved on the interviewer's laptop before he or she administers the survey. When the interview gets to a point where roster information is collected, the data from the previous round's roster are often used as the base for the current roster. The respondent verifies and updates the information. If no changes have occurred since the last interview-for example, if exactly the same people live in the respondent's household-then the current round's roster will be the same as the one from the previous round.
For example, the interviewer reads a list of all of the people on the household roster from the last interview. The respondent first states whether any of those people have moved out of the household and then reports new household members. If any members remain from the previous year, their information-date of birth, sex, race/ethnicity, etc.-is carried over from the previous interview, and any missing data are collected. This method is more efficient than asking the respondent to report all household members every year.
Raw data collection
After the respondent and interviewer review and update the roster from the previous round, the survey collects current information. For example, new people might have moved into the household, so the interviewer asks the respondent about their characteristics. At this point, the respondent is done answering questions that will fill up the data grid on a particular topic.
Roster creation and roster sort
Using the updated roster from the previous round and the new raw data just collected, the computer creates a new roster for the current round. For example, the employer roster contains the following information for each job: a unique identification number for the employer, employment dates, whether the job was current at the interview date, whether the job was in the military, and whether the job was an internship. If the respondent had held the job at the time of the previous interview, the start date and employer identification number are carried over from the old roster, and the other information is taken from the questions at the beginning of the employment section for the current year. Similarly, the household roster contains information from the previous interview about household members reported at that time and data from the current interview about new household members.
In some cases, the computer also sorts the roster and puts the items in order based on a specified variable. For example, in the round 1 household roster, all youths in the age range of the NLSY97 cohort were listed first, and then all other household members were listed from oldest to youngest. The employer roster is sorted by job end date so that the most recent jobs are listed first.
Roster use in the interview
Finally, the roster is used to determine the order in which the other questions about each topic are asked. In most cases, the survey collects far more information than is stored in the actual roster, and the answers to these questions remain outside the roster as raw data. So that the interview makes sense to the respondent, these additional questions are asked about the people or things on the roster in the order that the people or things are listed.
For example, the respondent first answers questions about industry, occupation, rate of pay, etc., for the first employer listed on the roster. The same questions are then asked about the second job, then the third job, and so on. Similarly, the first set of questions about household members refers to the first person listed on the roster. When all of those questions have been answered, the same questions are asked about the second person, the third person, etc.
Example: Creation and use of the employer roster
The following example illustrates the structure and use of the employer roster. Most aspects of this example apply to other NLSY97 rosters as well.
Roster creation in round 1
Raw data collection. The round 1 survey asked for the names of all employers for whom the respondent had worked since age 14. Assume that a respondent named Emma reported delivering the Smalltown Press when she was 14, then switching companies and delivering the County Register, and finally working in her parents' business, Peel's Corner Store, at the time of the round 1 interview. For this example, the newspaper delivery jobs are assumed to be employee jobs and not freelance-type work. The survey then assigned a unique identification number (UID) in the order the jobs were reported: 9701 for the Smalltown Press, 9702 for the County Register, and 9703 for Peel's Store.
Roster creation and roster sort. After the UIDs were assigned, Emma reported the dates she started and stopped working for each employer. At this point, the survey program sorted the jobs according to stop date, so that the most recent employer was employer #01, the next most recent was employer #02, and so on. Therefore, Peel's Store (UID 9703) became job #01 on the roster, the County Register (UID 9702) was listed as job #02, and the Smalltown Press (UID 9701) was listed third. Key information about each employer, including the unique ID number and dates of employment, was organized in the employer roster. All of the information about Peel's Store is located in variables numbered #01 in the title, the County Register data are in variables numbered #02, and so on.
|
Employer |
UID |
Round 1 Roster Line # |
|---|---|---|
|
Smalltown Press |
9701 |
03 |
|
County Register |
9702 |
02 |
|
Peel's Store |
9703 |
01 |
Roster use in the interview. Throughout the rest of the employment section, the employer numbers remain constant, so that each variable containing, for example, the phrase "Job #03" or "Employer #03" refers to Emma's Smalltown Press job. Note that the Smalltown Press is not the third employer Emma reported at the beginning of the employment section of the interview. It became employer #03 during the roster sort because the other two jobs were more recent.
Roster creation in round 2
Data from previous interviews. The employer information was collected in a similar manner in subsequent rounds. Because data were available from the previous interview, they could be used in the construction of the round 2 roster. Before the survey was fielded, survey staff loaded information about each respondent into the interviewers' laptops. In Emma's case, part of this information would be the list of employers she reported in round 1.
Raw data collection. During the survey, respondents first provided information about employers who were current at the last interview date. Assume that Emma stated that she worked at Peel's Store for several months after the round 1 interview. Respondents next reported new employers since the last interview date in no particular order. Emma reported only one additional job, waiting tables at Steed's Diner after she turned 16. At this point UIDs were given to each employer. Because Peel's Store was previously reported, it already had a UID--9703--assigned during the last interview. Steed's Diner was a new employer in round 2, so it was given a UID of 9801.
Roster creation and roster sort. Emma then reported the date she stopped working at each job, and the roster was sorted according to these stop dates. At the round 2 interview, the diner job was more recent, so it was listed as job #01 on the roster, and the store became job #02. At this point, the roster contains information from multiple survey rounds. The UID and start date of the Peel's Store job are carried over from round 1, while the stop date of the store job and all the information about Steed's Diner comes from round 2. Because Emma had not worked for the Smalltown Press or the County Register since the round 1 interview, neither of those employers is listed on the round 2 roster.
|
Employer |
UID | Round 1 Roster Line # | Round 2 Roster Line # |
|---|---|---|---|
|
Peel's Store |
9703 | 01 | 02 |
|
Steed's Diner |
9801 | - | 01 |
Roster use in the interview. Just as in round 1, the employer numbers remain the same for the rest of the interview. As Emma answered questions about Steed's Diner, her rate of pay, hours worked, etc., were recorded in the "Employer #01" questions. Peel's Store data were recorded in the "Employer #2" series.
Roster creation in round 3 and subsequent surveys
Data from previous interviews. This is used in each round as it was in round 2. Data from earlier interviews is loaded into the interviewer's laptop before the survey begins so that it can be used in the current survey if applicable.
Raw data collection. During the survey, respondents first provide information about employers who were current at the last interview date. In response to these questions in round 3, Emma reported her ongoing employment at Steed's Diner, where she had been working in round 2. Respondents next report new employers since the last interview date in no particular order; this series includes a check of employers from prior to the date of the last interview to determine if the respondent has returned to a previous employer. At this point in round 3, Emma reported that she went back to work at the Smalltown Press for a 6-month period between rounds 2 and 3. Both employers retained their original ID numbers, 9801 for the diner and 9701 for the newspaper, despite the break in Emma's employment at the latter.
Roster creation and roster sort. The roster is again sorted according to the stop date of each job. As Emma's current employer, Steed's Diner is listed as job #01 on the round 3 roster. The Smalltown Press becomes job #02 since Emma left that job before the round 3 interview date. Jobs where employment ended before round 2 are not listed on the round 3 roster.
|
Employer |
UID | Round 1 Roster Line # | Round 2 Roster Line # | Round 3 Roster Line # |
|---|---|---|---|---|
|
Steed's Diner |
9801 | - | 01 | 01 |
|
Smalltown Press |
9701 | 03 | - | 02 |
Roster use in the interview. The roster line numbers are then used for the duration of the interview, as described above for rounds 1 and 2. In the example, information about Emma's employment at the diner is recorded in the "Employer #01" questions, while data about the newspaper are recorded in the "Employer #02" series.
This section includes the Use of the employer roster in analysis example.
The data set is organized so that rosters can easily be found and used in research. Because rosters present key pieces of information in a structured format, they are the best place to obtain that information. All variables found on rosters have "Roster Item" as their main area of interest. Each roster has a unique name that serves as the beginning of the question name for all variables on the roster; the same name appears at the beginning of the variable title for each item on the roster. Different rosters have been used in different rounds, depending on the topics included in the interview and the type of information collected. The roster names and question names are shown in Figure 4.
|
Roster |
Question Name |
R1 | R2-4 | R5 | R6 and up |
|---|---|---|---|---|---|
|
Household Information |
HHI2 (rd. 1), HHI (rds. 2-9) |
* | * | * | * |
|
Nonresident Roster |
NONHHI |
* | * | * | * |
|
Youth Information |
YOUTH |
* | |||
|
School Roster |
NEWSCHOOL |
* | * | * | |
|
Employer Roster |
YEMP |
* | * | * | * |
|
Freelance Jobs Roster |
FREELANCE |
* | * | * | |
|
Training Roster |
TRAINING |
* | * | * | * |
|
Biological Children Roster |
BIOCHILD |
* | * | ||
|
Biological/Adopted Children Roster |
BIOADOPTCHILD |
* | * | ||
|
Parent Household Information |
PARHHI |
* | |||
|
Parent Youth Information |
PARYOUTH |
* | |||
|
Partner/Spouse |
PARTNERS |
* | * | * | * |
|
Other parents of respondent's children Note 1 |
OTHERPARENTS |
collapsed | |||
|
Partner/spouse information Note 1 |
CUMPARTNERS |
collapsed | |||
|
Note 1: These are collapsed rosters. The variables combine information across survey rounds. All respondents are represented in the roster, regardless of whether they were interviewed in the most recent round. These variables are listed as "XRND" rather than being associated with a survey year in the data. |
|||||
Important information: Locating rosters
Researchers can locate rosters in the data set by looking at the roster item area of interest, by selecting the appropriate question name, or by searching the any word in context index for variables with "ros" or "roster" and the name of the roster of interest in the title.
When the NLSY97 data set was initially created, variables could only be assigned to one area of interest. The newer data extraction software permits variables to be linked to multiple areas of interest. However, additional areas have not been assigned to every variable. Because roster items were initially located in the roster item area of interest, they may not be grouped with the rest of the data on a particular topic. For example, the school roster variables may not appear if the user searches for the "School Experience" area of interest. For this reason, it is very important that users become familiar with the rosters used in the data set. If a roster is available on the topic of a particular research project, users should always locate that roster using one of the search techniques mentioned above and examine it before using the other (non-roster) variables that relate to their research.
Using rosters in single-round analyses
When looking at the data set, users will notice that many questions are repeated for each person or thing on the roster, and the titles for these repeated questions include a number. This number indicates the line on the roster that corresponds to the person or item being described in that variable. For example, the question "Self-Employed Business/Industry Job 02" indicates the industry of the second job listed on the respondent's self-employment roster. The researcher may then want to examine information such as the respondent's start and stop dates or rate of pay for that job. To find this information, he or she can then look at the data for those items contained in the roster for job #02, or the self-employment job that is on the second line of the roster. For all other questions asked after the roster was created in that same survey year, job #02 will refer to the same self-employment job.
Users should be aware that, in some cases, the information contained in the rosters actually appears in the data set more than once. As Figure 1 suggests, data may first be included at the point in the interview when the information was actually collected. For example, the round 1 screener question SE-28 asked the household informant for the date of birth of each household member. After all the raw data had been gathered, the computer sorted all the answers and created the household roster. At this point the date of birth information is also located in the round 1 roster variables named HHI2_DOB. In the case of the round 1 household roster, both the raw data and roster items are included in the data set.
In other cases, the raw answers may be blanked out of the public use data set. If a reference number is not listed for a given question in the questionnaire, then that raw data item may only be represented in roster form. For example, answers to the raw data questions used to create the employer roster are blanked out and do not appear in the data set. In the printed questionnaire, these questions have no reference numbers. However, all of the data collected in these questions (except for confidential information like the name of the employer) appears in the employer roster.
Important information: Roster data
Even though the data may appear more than once, survey staff strongly recommend that researchers use the roster information rather than the raw data whenever possible. Survey staff are working to eliminate these duplicate sources of information.
For some variables, the roster information may be more accurate because some rosters are updated during the interview if the initial report was inaccurate. When survey staff prepare the data for release, they clean up the rosters if necessary but do not necessarily clean the corresponding raw data. Finally, because many rosters are sorted in a particular order, the number of a person or item on the roster will not match the number in the questions that precede roster creation. For example, in the household screener (the SE questions), person #01 is the first household resident mentioned to the interviewer. In the household roster and all later interview questions, person #01 is the oldest person in the household who was eligible for the NLSY97. Person #01 in the SE questions might be person #05 on the roster. It can be very difficult to determine to which person, school, or job a pre-sort question refers. For all of these reasons, roster data are always preferable to raw data in cases where both are available.
Using rosters from more than one round
Because the NLSY97 is a longitudinal survey, researchers often want to link data across survey rounds. However, household residents, jobs, and so on may move around on the roster in different interviews. That is, a father who was listed third on the roster in round 1 might move to position 2 or 4 in round 2. The unique identification numbers (UIDs) are the key to finding the same person or thing in different rounds. Most of the rosters contain variables assigning a unique number to each person or thing listed. This number never changes and can be used to link roster items across rounds. In some cases, it also makes it possible to link people between two different rosters in the same survey. For example, beginning in round 2 the unique ID listed for a child on the biological children roster is the same one assigned to that child on the household roster. Researchers can therefore examine data on both rosters about the same child.
An additional feature of most unique ID numbers is that they incorporate an indicator of the round in which the person or item was first reported. For example, IDs of roster items reported in round 1 may begin with "1" or "97," while those first reported in round 2 begin with "2" or "98." (Beginning with round 3, 4-digit years are used so that IDs begin with "1999" rather than just "99.") UIDs for people on the household roster are constructed in a slightly different manner; researchers should refer to Household Composition for more information.
Example: Use of the employer roster in analysis
Continuing the above example, this section explains how to use rosters in data analyses. Although the employer roster is used in the example, most aspects apply to other NLSY97 rosters as well. Emma's information, as organized in the employer rosters, can be used to examine the characteristics of her jobs at the date of each interview or over time. This example focuses primarily on the round 2 employer roster, but use of the roster is similar in each subsequent round.
As described above, Emma worked for Peel's Store and Steed's Diner during the period between the round 1 and round 2 interviews. Information about these employers was sorted and a roster constructed with the most recent employer appearing first. A researcher using these data would need to be aware of the impact of roster construction.
Because the roster is sorted and employers reported in different rounds may be mixed, variables with "Employer #01" in the title do not necessarily refer to employer number 9701, 9801, etc. The #01 refers solely to the order of the job as listed on the current year's roster. The unique identification numbers provide a crosswalk between the two systems of identification. The UIDs also allow users to link employers across survey rounds and to identify the round in which an employer was first reported.
For example, Emma's value for the round 2 variable R24761., "YEMP, Employer 02 Unique ID (Ros Item)," would be 9703-Peel's Store. The user can identify this as an ID assigned in round 1 because it starts with "97," and look at the round 1 UID variables (R05311.-R05317.) to match the employer. In Emma's case, the variable for employer #01 in round 1 would have UID 9703. Therefore, the researcher knows that information about employer #01 in round 1 refers to the same job as variables about employer #02 in round 2. The variables from the two rounds can then be compared to determine if there were any changes in characteristics such as hours worked, rate of pay, occupation, etc.
The roster line numbers and UID variables in the event history data work in the same way. For example, a researcher might want to know Emma's employment status in the first and last week of 1998. In the first week of 1998 (variable EMP_STATUS.01.98), Emma was working at her parents' store, so the status variable would have a value of 9703. Using this UID, researchers can link that job to all of the other information collected during the interview. For the last week of 1998 (variable EMP_STATUS.01.98), when Emma was working at Steed's Diner, the status variable would have a value of 9801. The second set of event history variables, the start and stop dates of each job, uses the roster line numbers. For these variables, the number in the variable title refers to the same job as in the main data set. For example, in the main round 2 data Peel's Store is job #02. The start and stop dates for Peel's Store in the event history data (variables EMP_START_WEEK.02 and EMP_END_WEEK.02) will also have #02 in the variable title.
Household Information
PREFIX = "HHI" (e.g., HHI_AGE.01); in round 1 only prefix was "HHI2" (e.g., HHI2_AGE.01)
|
Variable Name |
Title: All end in (Scr Ros Item) |
R1 | R2 | R3-6 | R7 | R8 | R9-11 | R12-14 |
|---|---|---|---|---|---|---|---|---|
|
_AGE |
Age of HH Member xx as of Intdate |
* | * | * | * | * | * | * |
|
_AGEEST |
Estimated Age of HH Member xx as of Intdate |
* | * | * | * | * | ||
|
_ASVAB |
Was HH Member xx Flagged for Asvab |
* | ||||||
|
_CHILDID |
ChildID HH Member xx |
* | * | * | * | * | ||
|
_DADID |
ID Number of HH Member xx Bio Dad |
* | ||||||
|
_DOB (rd 1) |
Date of Birth of HH Member xx (rd 1) |
* | * | * | * | * | * | |
|
_DEGREE |
HH Member xx Highest Degree Earned |
* | * | * | * | * | ||
|
_EMPLOYED |
Employment Status of HH Member xx (rd 1) |
* | * | * | * | * | * | * |
|
_ENROLLNEXT |
Will HH Member xx Be Enrolled Next Fall |
* | ||||||
|
_ENROLLSTAT |
Is HH Member xx Currently Enrolled |
* | * | * | * | * | * | |
|
_ETHNICITY
|
Is HH Member xx Hispanic? (rd 1) |
* | * | * | * | * | * | * |
|
_FIRSTLIVE |
HH Member xx Date First Lived in HH |
* | * | |||||
|
_HHFLAG |
HH Member xx Status |
* | * | * | * | * | * | |
|
_HHI1ID |
ID of HH Member xx from HHi1 Roster |
* | ||||||
|
_HIGHGRADE |
HH Member xx Highest Grade Completed |
* | * | * | * | * | * | * |
|
_ID |
HH Member xx ID |
* | ||||||
|
_INCOME |
What Is HH Member xx Monthly Income? |
* | * | * | ||||
|
_INFORMANT |
Is HH Member xx the Informant |
* | ||||||
|
_MARSTAT |
HH Member xx Marital Status |
* | * | * | * | * | * | * |
|
_MOMID |
HH Member xx Bio Moms ID |
* | ||||||
|
_PARENTUID |
HH Member xx Parent UID |
* | * | * | * | * | ||
|
_PARTNER |
HH Member xx Have a Partner |
* | ||||||
|
_PARTNERID |
ID of HH Member xx Partner |
* | ||||||
|
_RACE |
Race of HH Member xx (rd 1) |
* | * | * | * | * | * | * |
|
_RELIGION |
HH Member xx Religious Preference |
* | * | * | ||||
|
_RELY |
Relationship of Person xx to Respondent (rd 1) |
* | * | * | * | * | * | * |
|
_RELx, _RELxx |
Relationship of Person x to HH Member xx |
* | ||||||
|
_REVDOLEL |
Is HH Member xx DOLEligible (Revised) |
* | ||||||
|
_REVETPEL |
Is HH Member xx ETPEligible (Revised) |
* | ||||||
|
_REVSTPEL |
Is HH Member xx STPEligible (Revised) |
* | ||||||
|
_SEX |
Gender of HH Member xx (rd 1) |
* | * | * | * | * | * | * |
|
_SPECIAL |
HH Member xx Approved Special Accommodations |
* | ||||||
|
_SPOPARID |
ID of HH Member xx Spouse or Partner |
* | ||||||
|
_SPOUSEID |
ID of HH Member xx Spouse in HH |
* | ||||||
|
_UID |
HH Member xx Unique ID |
* | * | * | * | * | * | * |
NONHHI Roster (Non-resident relative enumeration)
PREFIX = "NONHHI" (e.g., NONHHI_AGE.01)
|
Variable Name |
Title: All end in (Scr Ros Item) |
R1 | R2 | R3 | R4 | R5 | R6 | R7-14 |
|---|---|---|---|---|---|---|---|---|
|
_AGE |
Age Non-Res Member xx at Interview Date (rd 1) |
* | * | * | * | * | * | * |
|
_ADOPTEDOUT |
Nonres Memb xx was Adopted Out |
* | * | * | ||||
|
_BDATE |
HH Member xx Birthdate (rd 3-5) |
* | * | * | * | * | ||
|
_CHILDID |
Nonres Member xx Child ID |
* | * | * | * | * | ||
|
_DECEASED (rd 1) |
Is Non-Res Member xx Deceased |
* | * | * | * | * | * | * |
|
_DEGREE |
Non-Res Member xx Have a Degree |
* | ||||||
|
_EMPLOYED |
Employment Status of Non-Res Member xx |
* | ||||||
|
_ETHNICITY |
Is Non-Res Member xx Hispanic (rd 1) |
* | * | * | * | * | * | * |
|
_FLAG (rd 1) |
How Is Non-Res Member xx Flagged (rd 1) |
* | * | * | * | * | * | * |
|
_HIGHGRADE |
HGC by Non-Res Member xx |
* | ||||||
|
_LIVEDWITH |
Nonres Member xx Live with R since DLI? |
* | * | |||||
|
_MARSTAT |
Marital Status of Non-Res Member xx (rd 1) |
* | * | * | * | * | * | * |
|
_PARENTUID |
Nonres Member xx Parent UID |
* | * | * | * | |||
|
_RACE |
Race of Non-Res Member xx (rd 1) |
* | * | * | * | * | ||
|
_RELATION (rd 1) |
Relationship of Non-Res Member xx to Youth (rd 1) |
* | * | * | * | * | * | * |
|
_SEX |
Gender of Non-Res Member xx (rd 1) |
* | * | * | * | * | * | * |
|
_UID |
Unique ID of Non-Res Member xx (rd 1) |
* | * | * | * | * | * | * |
|
Note 2: After round 5 the way race is asked in the questionnaire changed; it was not possible to maintain the race variable on the NONHHI roster since this roster is not directly updated during the survey. Users who need race information may be able to retrieve it from an early round, or from the HHI roster if the person ever re-entered the respondent's household. |
||||||||
PARTNERS Roster and CUMPARTNERS Roster (Youth partners)
PREFIX = "PARTNERS" (e.g., PARTNERS_xxxxx.01) and ("CUMPARTNERS" (e.g., CUMPARTNERS_xxxxx.01)
Note: A PARTNERS Roster is created for each survey round. Then, the CUMPARTNERS Roster is created as a collapsed roster which contains data from the most recent round in which each respondent was interviewed. Both rosters are represented here as the items on the rosters are very similar.
|
Variable Name |
Title: All end in (Ros Item) |
R1-8 | R9-14 | CUM (XRND) |
|---|---|---|---|---|
|
_CHILDWITH |
R Had Child With Partner |
* | * | * |
|
_CURRENT |
R Was Living With Partner At Interview |
* | * | * |
|
_ID |
ID Of R's xx Partner |
* | * | * |
|
_SEX |
Partner or Spouse xx Gender (PARTNERS) |
* | * | |
|
_STARTDATE |
Date R Started Living With Partner |
* | * | * |
|
_STOPDATE |
Date R Stopped Living With Partner |
* | * | * |
|
_STATUS (PARTNERS) |
Marital Status with R at Time of Interview (PARTNERS) |
* | * | * |
|
_UID |
UID of R's xx Partner (rds 1-4) |
* | * | * |
BIOChild Roster (Youth's children)
PREFIX = "BIOCHILD" (e.g., BIOCHILD_BDATE.01)
|
Variable Name |
Title: All end in (Ros Item) |
R1 | R2 | R3 | R4 |
|---|---|---|---|---|---|
|
_BDATE |
Birthdate of R Bio Child xx, Final (rd 1) |
* | * | * | * |
|
_DEAD |
Is R Bio Child xx Deceased, Final (rd 1) |
* | * | * | * |
|
_DOD |
Bio Child xx Date of Death |
* | * | * | |
|
_ID |
ID Number of Bio Child xx (rd 1) |
* | * | * | * |
|
_RESIDE |
Does R Bio Child xx Reside in Household, Final (rd 1) |
* | * | * | * |
|
_SEX |
Gender of R Bio Child xx, Final (rd 1) |
* | * | * | * |
|
_PARENTUID. xx |
ID of Other Parent of R Bio Child xx (rd 1) |
* | * | * | * |
|
_UID. xx |
Bio Child Unique Household ID Number xx ID |
* | * | * | * |
BIOADOPTChild Roster (Respondent's children)
PREFIX = "BIOADOPTCHILD" (e.g., BIOADOPTCHILD_SEX.O1)
|
Variable Name |
Title: All begin with BIOADOPTChild and end in (Ros Item) |
R5-11 | R12-14 |
|---|---|---|---|
|
_ADOPTED |
Child xx Adopted Status |
* | * |
|
_ADOPTEDOUT |
Adopted Out Status |
* | * |
|
_BDATE |
Biological/Adopted Child xx Bdate (other rds) |
* | * |
|
_CHILDID |
Biological/Adopted Child xx ID |
* | * |
|
_DOD |
Biological/Adopted Child xx Date of Death (rd 5) |
* | * |
|
_DEAD |
Biological/Adopted Child is Deceased |
* | * |
|
_PARENTUID |
Biological/Adopted Child xx Parent ID |
* | * |
|
_RESIDE |
Biological/Adopted Child xx Resides in Rs HH (rd 5) |
* | * |
|
_SEX |
Biological/Adopted Child xx Sex |
* | * |
|
_UID |
Biological/Adopted Child xx Unique ID Number ID (rd 5) |
* | * |
|
_BIRTHWTLBS |
Biological/Adopted Child xx Birth Weight - Pounds |
* | |
|
_BIRTHWTOZ |
Biological/Adopted Child xx Birth Weight - Ounces |
* |
OTHER PARENT Roster (Other parent of respondent's children)
PREFIX = "OTHERPARENTS" (e.g., OTHERPARENTS_AGE.01)
Note: This is a collapsed roster and contains data from more than one survey round. It includes information for all respondents, regardless of whether they were actually interviewed in the most recent round. In Investigator, the survey year is listed as "XRND".
|
Variable Name |
TAll begin with OTHERPARENT and end in (Ros Item) |
|---|---|
| _AGE | Age of Other Parent xx of Rs Child as of Intdate |
| _CARES | How Much R Cares for Other Parent xx |
| _CHILDID1 | ID of Other Parent xx First Child with R |
| _CHILDID2 | ID of Other Parent xx Second Child with R |
| _CHILDID3 | ID of Other Parent xx Third Child with R |
| _CHILDID4 | ID of Other Parent xx Fourth Child with R |
| _CHILDID5 | ID of Other Parent xx Fifth Child with R |
| _CHILDID6 | ID of Other Parent xx Sixth Child with R |
| _CHILDRANK | Rank Order by Child of Info about Other Parent xx |
| _CLOSE | How Close R Is to Other Parent xx |
| _CONFLICT | Amt of Conflict between R and Other Parent xx |
| _DEGREE | Other Parent xx Highest Degree Earned |
| _EMPLOYED | Other Parent xx Is Employed |
| _ENROLLSTAT | Is Other Parent xx Currently Enrolled |
| _ETHNICITY | Other Parent xx Ethnicity |
| _GOVTAID | Other Parent xx Is Receiving Govt Aid |
| _HGC | Other Parent xx Highest Grade Completed |
| _INCOME | Other Parent xx Monthly Income |
| _RACE | Other Parent xx Race |
| _RELBIRTH | RELATIONSHIP with Other Parent xx When Bio Child Born |
| _RELIGION | Other Parent xx Religious Preference |
| _RELPREG | Sexual Rltnshp W/ Other Parent xx When Became Pregnant |
| _ROUND | Round Data about Parent xx Was Collected |
| _SOURCE | Source of Parent xx Data |
| _UID | Other Parent xx Unique ID |
NEWSCHOOL Roster (Respondent's schools)
PREFIX = "NEWSCHOOL" (e.g., NEWSCHOOL_PERIODS.01)
|
Variable Name |
Title: All begin with NEWSCHOOL and end in (Ros Item) |
R1 | R2-3 | R4 | R5 | R6 | R7-8 | R9 | R10 | R11-12 | R13-14 |
|---|---|---|---|---|---|---|---|---|---|---|---|
|
_PERIODS |
Number of Times R Enrolled in School xx (rd 2) |
* | * | * | * | * | * | * | * | * | |
|
_START1 |
Month/Year R Start 1st Enrollment in School xx |
* | * | * | * | * | * | * | * | * | |
|
_START2 |
Month/Year R Start 2nd Enrollment in School xx |
* | * | * | * | * | * | * | * | * | |
|
_START3 |
Month/Year R Start 3rd Enrollment in School xx |
* | * | * | * | * | * | ||||
|
_STOP |
Month/Year R End Enrollment in School |
* | |||||||||
|
_STOP1 |
Month/Year R End 1st Enrollment in School xx |
* | * | * | * | * | * | * | * | * | |
|
_STOP2 |
Month/Year R End 2nd Enrollment in School xx |
* | * | * | * | * | * | * | * | * | |
|
_STOP3 |
Month/Year R End 3rd Enrollment in School xx |
* | * | * | * | * | * | ||||
|
_SCHCODE |
School Code Elementary, Middle, High, College |
* | * | * | * | * | * | * | * | * | * |
|
_INTERVIEW |
Which Survey Round School xx Reported in (rds 1-2) |
* | * | * | * | * | * | * | * | * | * |
|
_TYPE |
Type of School xx R Has Attended |
* | * | * | * | * | * | * | * | * | * |
|
_PUBID |
PUBID of School xx R Has Attended |
* | * | * | * | * | * | * | * | * | * |
|
_LEFT |
Reason Left School xx |
* | * | * | * | * | * | * | * | * | * |
|
_LEFT2 |
Reason Left School xx - 2nd Time |
* | * | * | |||||||
|
_GED |
GED Status of College Enrollment in School xx |
* | * | * | * | * | * | * | * | ||
|
_RECOVERED |
School xx College Information Recovered in Round 10 |
* |
YEMP Roster (Youth's employers)
PREFIX = "YEMP" (e.g., YEMP_CURFLAG.01)
|
Variable Name |
Title: All end in (Ros Item) |
R1 | R2-3 | R4-5 | R6-7 | R8 | R9 | R10-14 |
|---|---|---|---|---|---|---|---|---|
|
_ASSIGNMT |
Assignmt Job xx |
* | * | |||||
|
_CURFLAG |
Was R Currently Employed at Interview Date Job xx (rd 1) |
* | * | * | * | * | * | * |
|
_INDCODE |
Type of Bus or Industry Code (1990 Census 3-Digit) xx |
* | * | * | ||||
|
_INDCODE-2002 |
Type of Bus or Industry Code (2002 Census 4-Digit) xx |
* | * | * | * | * | * | * |
|
_INTERN |
Is This an Internship Employer Job xx |
* | * | * | * | * | * | * |
|
_MILFLAG |
Is Employer xx a Military Employer |
* | * | * | * | * | * | |
|
_MILCODE |
Employer xx Military Code |
* | * | * | * | * | * | |
|
_MILPAY |
Employer xx Military Pay Grade |
* | * | * | * | * | * | |
|
_OCCODE |
Occupation/Job Code (1990 Census 3-Digit) xx |
* | * | * | ||||
|
_OCCODE-2002 |
Occupation/Job Code (2002 Census 4-Digit) xx |
* | * | * | * | * | * | * |
|
_YEMP_SELFEMP |
Is Employer xx a Self-Employed Job? |
* | * | * | * | * | ||
|
_STARTDATE |
Employer Start Month/Day/Year Job xx (rd 1) |
* | * | * | * | * | * | * |
|
_STOPDATE |
Employer Stop Month/Day/Year Job xx (rd 1) |
* | * | * | * | * | * | * |
|
_UID |
Employer Unique ID Number Job xx (rd 1) |
* | * | * | * | * | * | * |
|
_RECOVERED |
Employer xx Job Information Recovered in Round 10 |
* | * |
Important information: Employment rosters
Beginning in round 4, the transition from the freelance section to the regular employee job section created a disconnect in unique ID codes (see the introduction to Appendix 2: Employment Variable Creation). If a respondent had a freelance job at age 16 with enough earnings to qualify as self-employed, and continued that job past his or her 18thbirthday, the job now appears, on the regular employer roster rather than the freelance roster. When the job was in the freelance section, it was assigned a freelance UID. However, these UIDs could not be transferred to the regular employer roster because the numbering system is different. On the other hand, it was misleading to assign a round 4 UID, when the self-employed job first appears on the regular employer roster, because the job was preexisting. So, to indicate that a self-employed job existed during a previous interview, it was assigned a UID of 199999 on the round 4 roster. If a self-employed job was new in the round 4 interview--it had never been reported in the freelance section--it was assigned a regular round 4 UID.
FREELANCE Roster (Respondent's freelance jobs)
PREFIX = "FREELANCE" (e.g., FREELANCE_JOBS-COD.01)
|
Variable Name |
Title: All begin with FREELANCE and end in (Ros Item) |
R1 | R2 | R3 | R4 | R5 |
|---|---|---|---|---|---|---|
|
_JOBS-COD |
Job Code Frame xx |
* | * | * | * | * |
|
_JOBS-NEWCOD |
Job Code Frame - Revised xx |
* | * | |||
|
_STARTDATEL |
Start Date Reported at DLI Job xx |
* | ||||
|
_STARTDATEC |
Start Date Current Freelance Job xx |
* | * | * | * | |
|
_STOPDATECU |
Stop Date Current Freelance Job xx |
* | * | * | * | |
|
_CURATLI |
Job Was Current at DLI Job xx |
* | ||||
|
_CURRNOW |
Job xx Is Current Freelance Job |
* | * | * | * | |
|
_STARTDATEI |
Start Date Info Job xx |
* | ||||
|
_UID |
Freelance Job xx Unique ID |
* | * | * | * | * |
TRAINING Roster (Respondent's training programs)
PREFIX = "TRAINING" (e.g., TRAINING_UID.01)
|
Variable Name |
Title: All begin with TRAINING and end in (Ros Item) |
|---|---|
| _UID | UID of Training Program xx |
| _STARTDATE | Startdate of Training Program xx |
| _STOPDATE | Stopdate of Training Program xx |
| _CURFLAG | Training Program xx Current |
| Note: All rounds have the same variables on the roster. | |
Additional roster variables
A handful of other variables have been listed as roster variables in various survey rounds. These special variables are summarized below.
|
Round |
Variable Name |
Title: All end in (Ros Item) |
Description |
|---|---|---|---|
|
1 |
PLACES_GETHOME | PLACES Time R Arrives Home after Regular Daily Activity xx | This roster describes places that a not enrolled/employed respondent usually goes. |
|
1 |
PLACES_GETTIME | PLACES Time R Leaves Home for Regular Daily Activity xx | |
|
2 |
OLDR1NONHHIPARENT_UID | UID of DLI Parent xx | These variables permit identification of parents in the parent loops at the beginning of the HHI section. See the note in the codebook for more information. |
|
2 |
OLDR1PARENT | UID of DLI Parent xx | |
|
3 |
PREVPARENT_UID | Prev HH Parent Unique Household ID Number xx ID | |
|
3 |
PREVNONHHIPARENT_UID | Prev NONHHI Parent Unique ID Number xx ID |
In round 1, a number of rosters were used to organize information from the Screener, Household Roster, and Non-Resident Roster Questionnaire. Some of this information was then transferred into the parent and youth interviews for verification and for use in determining question paths. Figure 5 identifies the key rosters in the round 1 survey and shows how they were used in different parts of the survey.
The YOUTH, PARHHI, and PARYOUTH rosters appeared only in the round 1 survey. The contents of these special rosters are listed following Figure 5. Other rosters in the figure also appeared in subsequent rounds and are listed in the previous section.
Figure 5. Construction and use of round 1 rosters
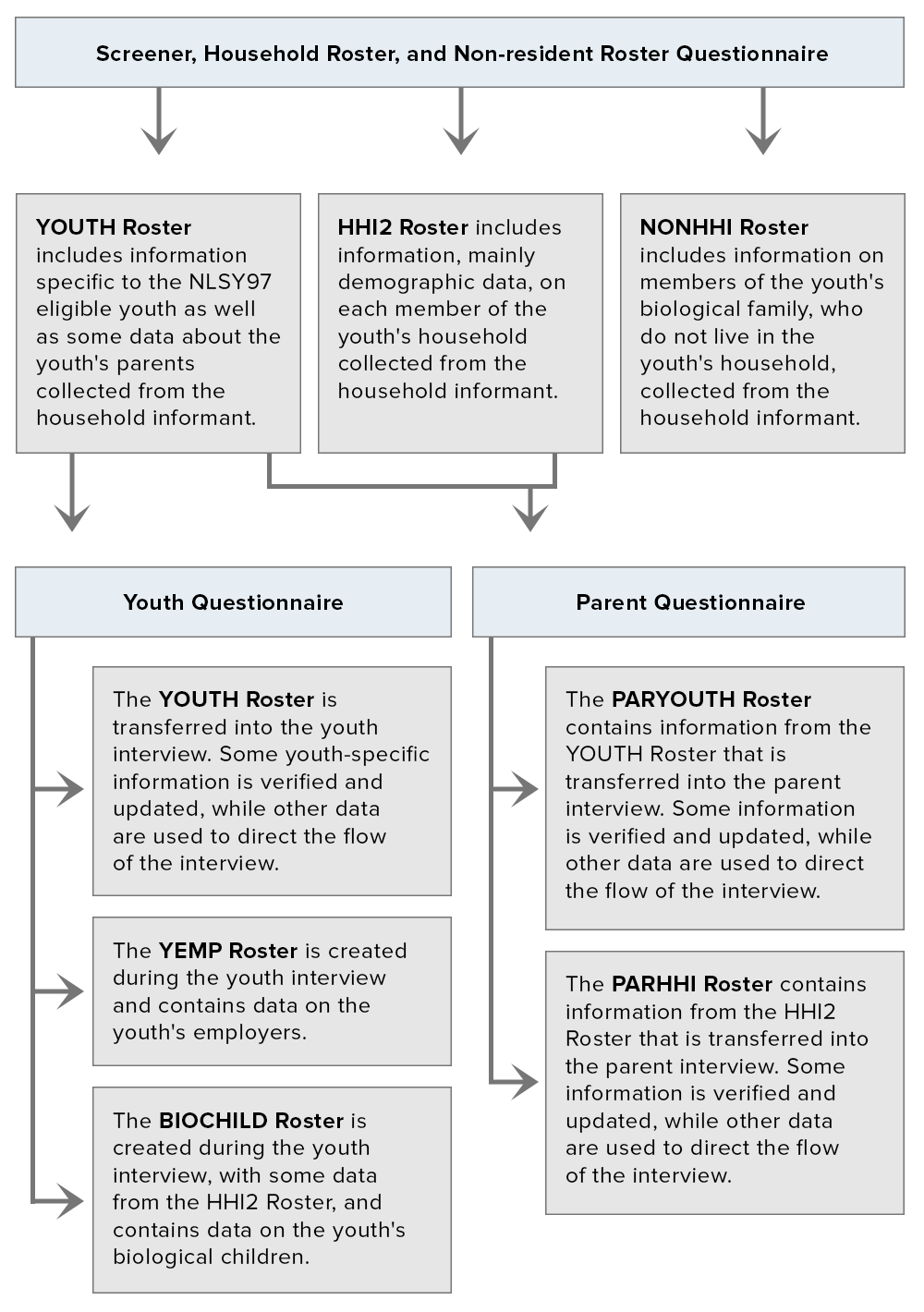
Click to enlarge Figure 5 | Read a text version of the Figure 5 flowchart
YOUTH Roster (Youth respondent information)
PREFIX = "YOUTH" (e.g., YOUTH_ADOPDADID.01)
|
Variable Name |
Title: All end in (Ros Item) |
|---|---|
| _ADOPDADID.01 | R 01 Adoptive Dads ID |
| _ADOPMOMID.01 | R 01 Adoptive Moms ID |
| _BOTHBIO.01 | Does R 01 Live with Both Bio Parents? |
| _DADID.10 | R 01 Bio Dads ID |
| _EMANCIPAT.01 | Is R 01 Emancipated? |
| _FOSTDADID.01 | R 01 Foster Dads ID |
| _FOSTMOMID.01 | R 01 Foster Moms ID |
| _GRADE.01 | R 01 Current Grade |
| _HHADOPTKID.01 | Does R 01 Have Any Adopted Kids in HH? |
| _HHBIOKID.01 | Does R 01 Have Any Bio Kids in HH? |
| _HHID.01 | R 01 HH ID Number |
| _HHSTEPKID.01 | Does R 01 Have Any Step Kids? |
| _ID.01 | R 01 ID Number |
| _MOMID.01 | R 01 Bio Moms ID |
| _NONR1DEAD.01 | Is R 01 1st Non-Resp Bio Parent Deceased? |
| _NONR1ID.01 | ID of R 01 1st Non-Resp Bio Parent |
| _NONR1INHH.01 | Does 1st Non-Resp Bio Parent of R 01 Live in HH? |
| _NONR1SEX.01 | Gender of R 01 1st Non-Resp Bio Parent |
| _NONR2DEAD.01 | Is R 01 2nd Non-Resp Bio Parent Deceased? |
| _NONR2ID.01 | R 01 2nd Non-Resp Bio Parents ID |
| _NONR2INHH.01 | Is R 01 2nd Non-Resp Parent in HH |
| _NONR2SEX.01 | Gender of R 01 2nd Non-Resp Bio Parent |
| _NRADOPTKID.01 | Does R 01 Have Any Non-Resident Adopted Kids |
| _NRBIOKID.01 | Does R 01 Have Any Non-Resident Bio Kids? |
| _NRDADID.01 | ID of R 01 Non-Resident Bio Dad |
| _NRMOMID.01 | ID of R 01 Non-Resident Bio Mom |
| _NRSTEPKID.01 | Does R 01 Have Any Non-Resident Step Kids |
| _PARENT.01 | Relationship of Resp Parent to R 01 |
| _PARENTGUAR.01 | Does R 01 Have a Resp Parent or Guardian in HH |
| _PARENTID.01 | ID of R 01 Resp Parent |
| _PARENTSEX.01 | Gender of R 01 Resp Parent |
| _SPOPARID.01 | ID of R 01 Spouse or Partner |
| _STEPDADID.01 | ID of R 01 Step Dad |
| _STEPMOMID.01 | ID of R 01 Step Mom |
PARHHI Roster (Household information in parent interview)
PREFIX = "PARHHI" (e.g., PARHHI_AGE.01)
|
Variable Name |
Title: All end in (Par Ros Item) |
|---|---|
| _AGE | Age of HH Member xx as of Interview Date |
| _AGEDOL | Age of HH Member xx as of 12/31/1996 |
| _DADID | Member xx Bio Dads ID |
| _DOB | Member xx Date of Birth |
| _DOLEL | Is HH Member xx Dol Eligible (Preliminary) |
| _ELIGIBLE | Member xx Dol, Etp or Stp Eligible |
| _EMPLOYED | Employment Status of HH Member xx |
| _ENROLLSTAT | Is HH Member xx Currently Enrolled |
| _ETPEL | Is HH Member xx Etp Eligible (Preliminary) |
| _GRADE | Member xx Current Grade |
| _HIGHGRADE | Member xx Highest Grade Completed |
| _ID | ID of HH Member xx |
| _MARSTAT | Member xx Marital Status |
| _MOB | Member xx Month of Birth |
| _MOMID | Member xx Bio Moms ID |
| _PARTNER | Member xx Have a Partner? |
| _RACE | Race of HH Member xx |
| _RELx, _RELxx | Relationship of Person xx to HH Member xx The relationship variables are provided for people 1-20. For example, REL1 provides the relationship of person 1 to household member xx. REL20 provides the relationship of person 20 to household member xx. |
| _REVDOLEL | Is HH Member xx Dol Eligible (Revised) |
| _REVETPEL | Is HH Member xx Etp Eligible (Revised) |
| _REVSTPEL | Is HH Member xx Stp Eligible (Revised) |
| _SEX | Member xx Sex |
| _SPOPARID | ID of HH Member xx Spouse or Partner |
| _STPEL | Is Member xx Stp Eligible (Preliminary) |
| Note: Many of the variables on this roster also appear on the HHI2 roster. The HHI2 roster has been cleaned, while this roster has not. Researchers may wish to use the HHI2 roster rather than the PARHHI roster in analyses. | |
PARYOUTH Roster (Youth information for parent interview
PREFIX = "PARYOUTH" (e.g., PARYOUTH_AGE.01)
|
Variable Name |
Title: All end in (Par Ros Item) |
|---|---|
| _ADOPDADID | Rs Adoptive Dads ID |
| _ADOPMOMID | Rs Adoptive Moms ID |
| _AGE | Age of R as of Interview Date |
| _AGEDOL | Age of R as of 12/31/96 |
| _BOTHBIO | Does R Live with Both Bio Parents? |
| _DADID | Rs Bio Dads ID |
| _DOB | Date of Rs Birth |
| _ELIGIBLE | Is R Eligible for Dol, Etp or Stp? |
| _EMANCIPAT | Is R Emancipated? |
| _FOSTDADID | Rs Foster Dads ID |
| _FOSTMOMID | Rs Foster Moms ID |
| _GRADE | Rs Current Grade |
| _HHADOPTKID | Does R Have Any Adopted Kids in HH? |
| _HHBIOKID | Does R Have Any Bio Kids in HH? |
| _HHID | Rs HH ID Number |
| _HHSTEPKID | Does R Have Any Step Kids? |
| _ID | Rs ID Number |
| _MARSTAT | Rs Marital Status |
| _MOMID | Rs Bio Moms ID |
| _NONR1DEAD | Is Rs 1st Non-Resp Bio Parent Deceased? |
| _NONR1ID | ID of Rs 1st Non-Resp Bio Parent |
| _NONR1INHH | 1st Non-Resp Bio Parent of R Live in HH? |
| _NONR1SEX | Gender of Rs 1st Non-Resp Bio Parent |
| _NONR2DEAD | Is Rs 2nd Non-Resp Bio Parent Deceased? |
| _NONR2ID | Rs 2nd Non-Resp Bio Parents ID |
| _NONR2INHH | Is Rs 2nd Non-Resp Bio Parent In HH |
| _NONR2SEX | Gender of Rs 2nd Non-Resp Bio Parent |
| _NRADOPTKID | Does R Have Any Non-Resident Adopted Kids |
| _NRBIOKID | Does R Have Any Non-Resident Bio Kids? |
| _NRDADID | ID of Rs Non-Resident Bio Dad |
| _NRMOMID | ID of Rs Non-Resident Bio Mom |
| _NRSTEPKID | Does R Have Any Non-Resident Step Kids |
| _PARENT | Relationship of Resp Parent to R |
| _PARENTGUAR | R Have a Resp Parent or Guardian in HH |
| _PARENTID | ID of Rs Resp Parent |
| _PARENTSEX | Gender of Rs Resp Parent |
| _SEX | Gender of R |
| _SPOPARID | ID of Rs Spouse or Partner |
| _STEPDADID | ID of Rs Stepdad |
| _STEPMOMID | ID of Rs Stepmom |