
NLSY97 respondents answer questions about current and previously held jobs; there is no limit to the number or types of jobs a respondent may report. These data are collected about every employer for whom the respondent worked since the last interview so that a complete picture of the respondent's employment can be constructed. Unlike earlier NLS surveys, the employment sections distinguish between four types of jobs: employee-type jobs, freelance jobs, self-employment, and military service.
This employment section of the guide starts with several overview sections that provide information needed to understand how job data are collected in the survey. Users are encouraged to review these introductory sections before proceeding to the specific topic(s) of interest among those listed in Table 1. Introductory sections include:
- Important information: Using employment data
- Employment questionnaire sections: Structure and variation across survey rounds
- Linking job information with employers
- The employer roster: How the Event History data collection process works (includes detailed example)
| NLSY97 User's Guide Topic | Round 1 Universe (Age as of interview date) |
Round 2 Universe (Age as of interview date) |
Round 3 Universe (Age as of interview date Note 1.1) |
Rounds 4-5 Universe (Age as of interview date) |
Rounds 6 and up Universe (Age as of interview date) |
|
|---|---|---|---|---|---|---|
| Employers & Jobs Details on the four types of job categories in the NLSY97: employee-type jobs, freelance, self-employed, and military service. R18 includes job task info. |
all resp. with freelance job >=14 with employee job >=16 for military service |
all resp. with freelance job >=14 with employee job >=16 for military service |
all respondents, except >=16 for military service |
all respondents, except >=16 for military service |
all respondents | |
| Fringe Benefits Benefits offered through employer such as health-related insurance, life insurance, retirement plan, etc. |
>=16, for each employee job lasting >=13 weeks |
>=16, for each employee job lasting >=13 weeks |
>=16, for each employee job lasting >=13 weeks |
>=16, for each employee job lasting >=13 weeks |
each employee job lasting >=13 weeks (starting in 2013, changed to job lasting >=26 weeks) | |
| Gaps in Employment Time gaps within and between jobs |
>=14 | >=14 | all respondents | all respondents | all respondents | |
| Industry Census industry codes for each job held by respondent |
>=14 with employee job or >=16 and self-employed |
>=14 with employee job or >=16 and self-employed |
all resp. with employee job or >=16 and self-employed |
all resp. with employee job or >=16 and self-employed |
all resp. with employee job or self-employed |
|
| Job Search | CPS Questions (job search questions based on the Current Population Survey) | >=15 | all respondents in round 4; not asked in round 5 | asked in round 10 | ||
| Employee Jobs Questions (job search questions asked of respondents who reported gaps in employment) | >=16 with employee job | >=16 with employee job | >=16 with employee job | >=16 with employee job | all resp. with employee job | |
| Labor Force Status Respondent's employment status in the week before survey, using CPS information. Available for rounds 1, 4, and 10. |
>=15 | all respondents (round 4) | all respondents (round 10) | |||
| Occupation Census occupation codes for each job held by respondent |
>=14 with employee job or >=16 and self-employed |
>=14 with employee job or >=16 and self-employed |
all resp. with employee job or >=16 and self-employed |
all resp. with employee job or >=16 and self-employed |
all resp. with employee job or self-employed | |
| Self-Employment Characteristics Details about freelance or self-employed jobs |
>=16 and earn >=$200/week | >=16 and earn >=$200/week | >=16 and earn >=$200/week | earn >=$200/week or born in 1980-82 (R4) or 1980-83 (R5) |
all respondents | |
| Tenure Weeks spent working at employee-type or freelance jobs |
all resp. with freelance job or >=14 with employee job |
all resp. with freelance job or >=14 with employee job |
all respondents | all respondents | all respondents | |
| Hours Spent at Work Usual hours respondent worked per week |
all resp. with freelance job or >=14 with employee job |
all resp. with freelance job or >=14 with employee job |
all respondents | all respondents | all respondents | |
| Wages Respondent's rate of pay |
all resp. with freelance job or >=14 with employee job |
all resp. with freelance job or >=14 with employee job |
all respondents | all respondents | all respondents | |
| Work Experience A description of the created variables researchers can use to construct a longitudinal record for the respondent's employment history |
>=14 | >=14 | all respondents | all respondents | all respondents | |
|
Note 1.1: All respondents were at least 14 years old by the round 3 interview date. |
||||||
Throughout the employment section, we refer to three different types of jobs. These are:
Employee jobs
For each employee-type job--defined as a situation in which the respondent has an ongoing relationship with a specific employer--youths age 14 and older are asked about the job's characteristics as of the time they started that job. The survey solicits similar end-date information for each employee-type job lasting more than 13 weeks (in 2013, this changed to each job lasting 26 weeks or more). For jobs that end after the respondent's 16th birthday (or for on-going jobs held by youths age 16 or older), detailed questions are asked about the workplace. Additional questions similar to the Current Population Survey (CPS), asked of respondents age 15 or older in the round 1 Youth Questionnaire, determined respondents' labor force status in the week before the interview. In round 4 and round 10, all respondents received the CPS section.
Freelance jobs
Questions specific to freelance employment--that is, jobs for which the respondent performed one or a few tasks for several people without a specific boss, or in which the respondent worked for himself or herself--are unique to the NLSY97. This survey captured many typical youth jobs, such as lawn-mowing and baby-sitting, which are often missing from an employment history. In this section of the survey, respondents age 14 and older were asked about their experiences with freelance jobs. For respondents age 12 or 13, the survey asked these freelance questions about all jobs (without explicitly distinguishing between employee and freelance jobs).
Self-employment
In rounds 1-3, respondents who were age 16 or older and who usually earned $200 or more per week at a freelance job were considered self-employed. Additional information was collected about those jobs as part of the freelance section of the survey. Starting in round 4, respondents were routed through different paths based on age. Those born in 1980-82 answered questions about self-employment in the regular employee jobs section of the questionnaire (regardless of amount earned at that job). Younger respondents born in 1983-84 who met the earnings requirement continued to list self-employment in the freelance section. In addition to answering the freelance or employee jobs questions, these respondents were asked to provide more information about their self-employment. See the Self-Employment Characteristics section for more details.
Important information: Using employment data
- Most age restrictions in the CPS, employment, and training sections of the questionnaire refer to age as of the survey date, rather than age as of December 31, 1996, as in all other sections. However, the check items that routed respondents through the rounds 4 and 5 employee and freelance sections were based on age as of December 31, 1996. Users should carefully examine the questionnaire and documentation to ensure that they have correctly identified the age restrictions for a given set of questions. Note that all respondents were at least 14 years old in round 3, so the age 14 restrictions were dropped beginning with that survey. All respondents were at least 18 years old in round 6, and the freelance section was dropped at that point.
- Users should also keep in mind that the NLSY97 questions based on the Current Population Survey (CPS) were only included in rounds 1, 4, and 10 of the surveys.
- These data are employer-based, not job-based. As a result, the information collected reflects the time a respondent spent with an employer (or self-employed) and not changes of responsibilities or jobs during that period. For linking employers across surveys, even when there are breaks in employment, see the Linking Jobs With Employers section.
- See the Self-Employment Characteristics section for information on the special case of respondents who had a freelance job classified as self-employment in rounds 1-3 and continued that job over into the regular employee jobs section in rounds 4-6.
Employment questionnaire sections: Structure and variation across survey rounds
The employment sections of the questionnaire are somewhat complex. Before beginning analysis, researchers must understand the structure of each round's questionnaire, particularly the way in which jobs are classified as employee, freelance, or self-employment. It is important to note that this classification depends in part on the survey round and the respondent's age.
In rounds 1 and 2, employee jobs were recorded in the first part of the YEMP section, administered only to respondents age 14 or older as of the interview date. The second part of the YEMP section collected information about freelance jobs of respondents age 14 and older and all jobs of respondents age 12 or 13 (the implicit assumption being that respondents younger than 14 are not likely to hold employee jobs). If the respondent was at least 16 years old and made at least $200/week in a freelance job, the job was classified as self-employment and an extra series of questions was asked during the freelance section.
In round 3, all respondents were at least age 14 by the interview date, so the age restriction for employee jobs was no longer necessary. The structure of the section remained largely the same, with a division between employee and freelance jobs. Self-employment was classified in the same way as in the earlier rounds.
In round 4, the section was redesigned. Respondents born in 1980-1982 (who were mostly age 18 and older when the round 4 field period began) were asked about employee jobs and self-employment at the same time. In addition, the minimum income requirement from the freelance section no longer applied; jobs could be classified as self-employment regardless of earnings. However, respondents born in 1983-1984 (who were mostly age 16 or 17 when the round 4 field period began) continued to describe employee and freelance jobs separately. For these respondents, data on self-employment jobs were still collected in the freelance section, and freelance jobs still had to meet the income criteria to qualify as self-employment.
The round 5 employment section followed similar age restrictions and question structure as the round 4 section. For this survey, respondents born in 1980-1983 (who were mostly age 18 and older when the round 5 field period began) were asked about employee jobs and self-employment. Respondents born in 1984 (who were younger than age 18 when the field period began) again described employee and freelance jobs separately.
Beginning in round 6, all respondents reported both self-employment jobs and employee jobs in the employer loop. The freelance section was dropped from the survey. From round 6 forward, information on self-employment mirrors that collected for regular employee jobs.
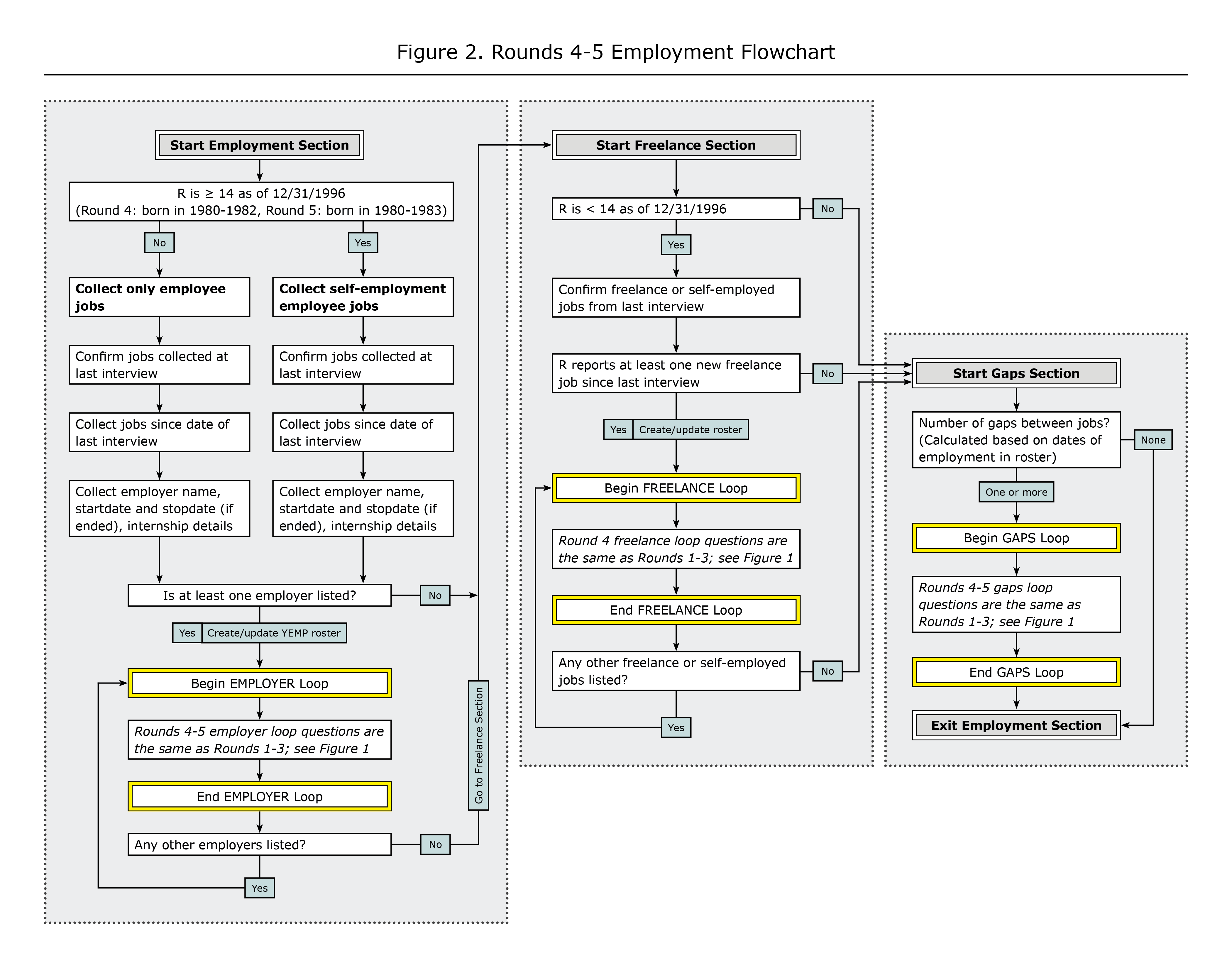
Figures 1–3 show flowcharts of the employment sections across survey rounds. They illustrate the main universe restrictions and the types of job-related questions asked of different respondent groups. They are not a complete representation of every question in the YEMP section of the questionnaire. Figure 1 focuses on rounds 1-3; users should note that questions asked only in rounds 2 and 3 are indicated in italics. Figure 2 illustrates the change in the structure of the section for rounds 4 and 5, and Figure 3 notes the changes beginning in round 6. References to groups of questions that are the same as previous rounds are indicated in italics.
Figure 1. Rounds 1-3 Employment Flowchart
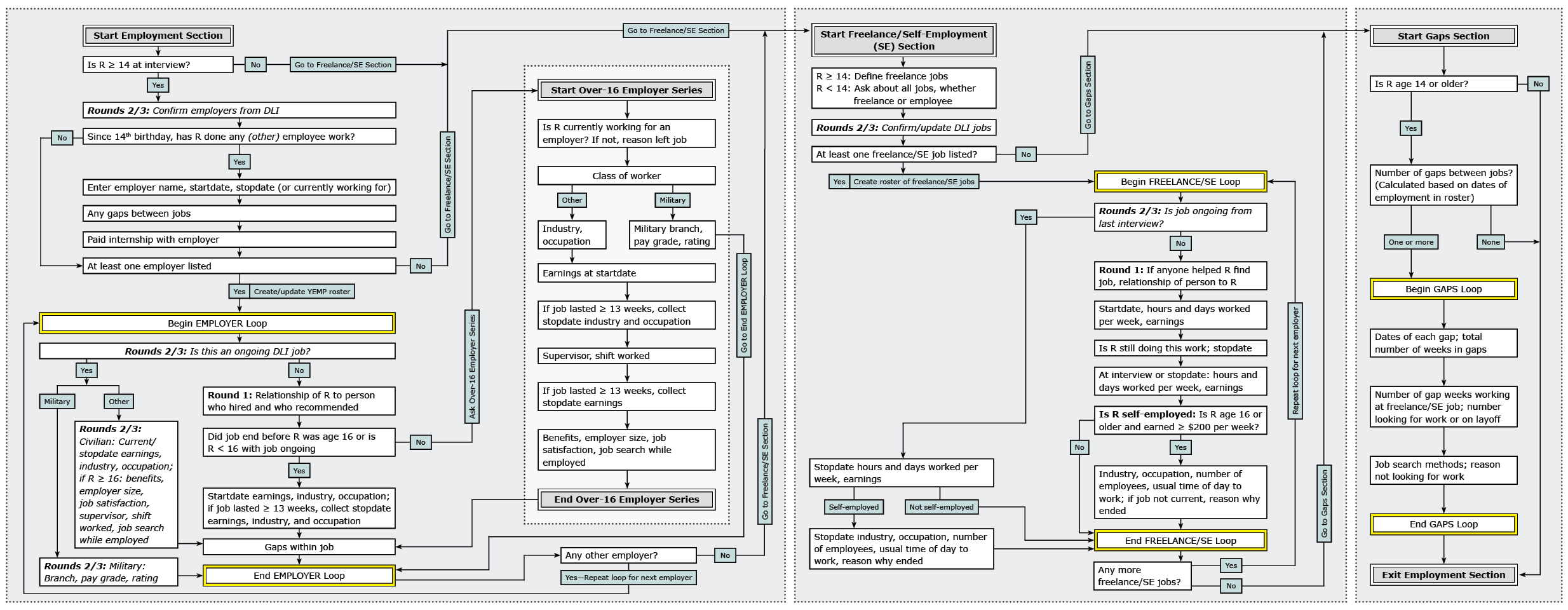
View larger image of Figure 1 | Read outline version of Figure 1
{kind=link}
Figure 2. Rounds 4-5 Employment Flowchart
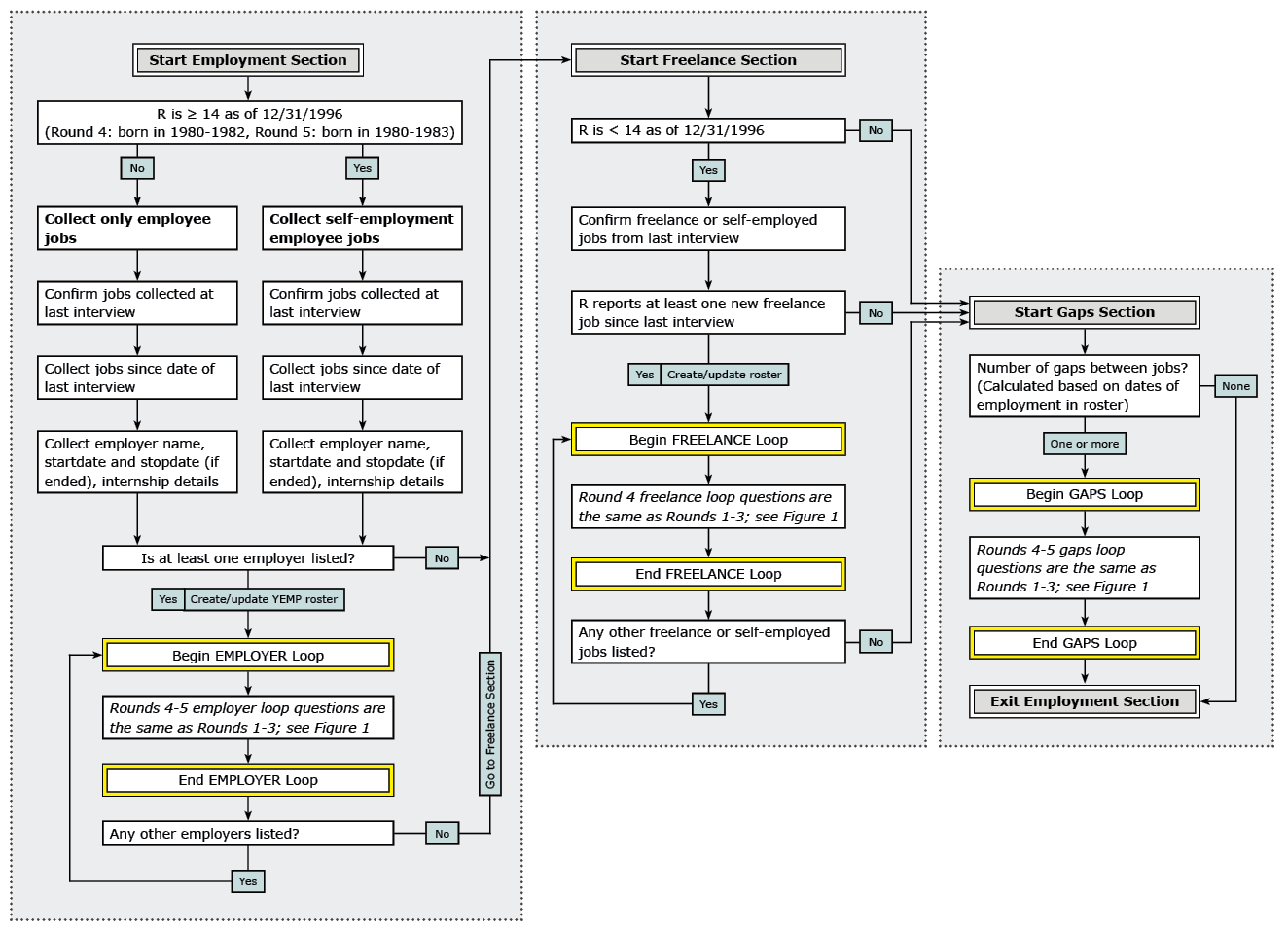
View larger image of Figure 2 | Read outline version of Figure 2
{kind=link}
Figure 3. Rounds 6 and up Employment Flowchart
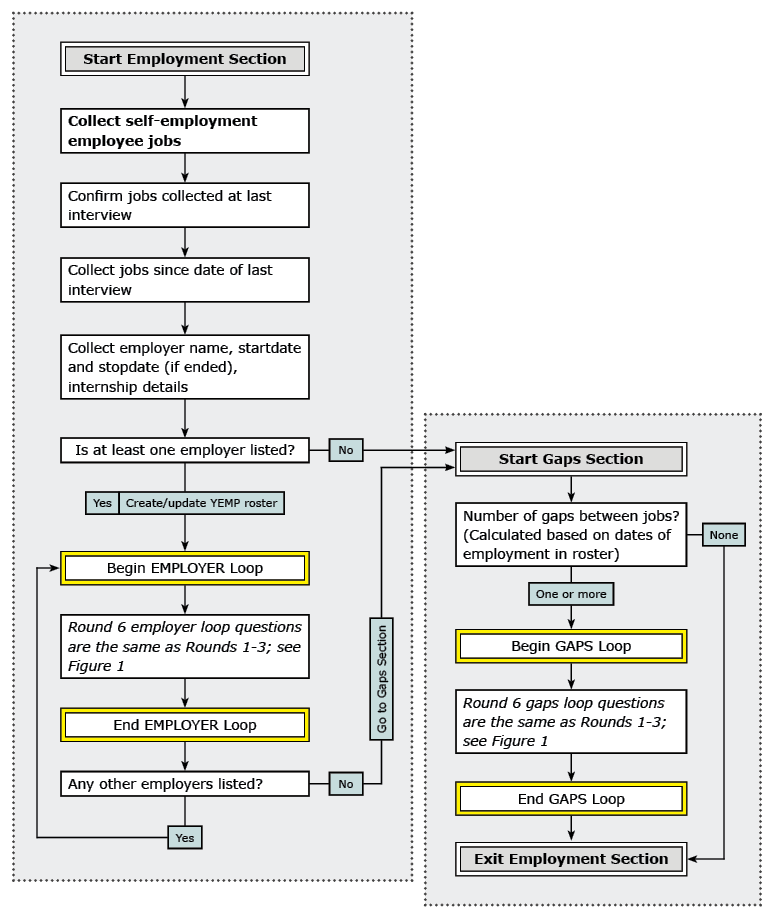
View larger image of Figure 3 | Read outline version of Figure 3
{kind=link}
Linking job information with employers
To associate job information with the correct employer, researchers need to understand how employment information is collected during the interview. The following paragraphs describe how the data are gathered and how employers can be identified in different types of questions and across survey rounds.
In round 1, any respondent who went through the employee-type jobs section was asked to provide the names of all the employers (including family businesses at which the respondent worked in an unpaid position) for whom he or she had worked since age 14. Then, in the YEMP-1800.xx variables, each employer was assigned a number (e.g., 9701, 9702, and so on through 9707 since the highest number of jobs reported was 7) in the order in which they were reported by the youth. This number is called the unique identification number (UID) for the employer.
After the round 1 employers were assigned a unique ID number, the respondent reported the dates he or she started and stopped working for each employer. (These questions are not represented in the data exactly as asked; they are reported in the roster variables YEMP_STARTDATE.xx and YEMP_STOPDATE.xx.) At this point, the survey program sorted the jobs by stop date so that the most recent employer was employer #01, the next most recent was employer #02, and so on. Key information about each employer, including the ID number and dates of employment, was organized in the employer roster. Throughout the rest of the employment section, the employer numbers remain constant, so that each variable containing, for example, the phrase "Job #01" or "Employer #01" refers to the same employer for a given respondent. In this case the variables would refer to the first employer on the roster, which is not necessarily the first employer reported by the youth at the beginning of the employment section of the interview.
Starting in round 2, the employer information was collected in a similar manner. Respondents reported all new employers since the last interview date in no particular order. As employers were reported, the CAPI program included a check for whether each employer had been reported in a previous interview. If the respondent reported a new employer, then the YEMP_UID.xx variables contain a new number, as shown in Table 2. If the employer had been previously reported, the employer kept the same ID number (9701-9707 for round 1 employers, 9801-9809 for round 2 employers, and so on) as it had in previous rounds. This system permits users to link employers across survey rounds, even if there was a break in employment, and to identify the round in which an employer was first reported. After the ID numbers were either continued from a previous round or newly assigned, the roster was sorted according to the stop date of each job. Therefore, employers from different rounds may be mingled on the roster; previous round employers do not necessarily precede current round employers. Note that old employers for whom the respondent has not worked since the last interview do not appear on the current round's roster.
| Round | Maximum Number of Jobs | Unique ID Number Range Note 2.1 |
|---|---|---|
| R1 | 7 | 9701-9707 |
| R2 | 9 | 9801-9809 |
| R3 | 9 | 199901-199909 |
| R4 | 9 | 200001-200009, 199998, 199999 |
| R5 | 8 | 200101-200109, 200099 |
| R6 | 11 | 200201-200209, 200199 |
| R7 | 10 | 200301-200310 |
| R8 | 7 | 200401-200407 |
| R9 | 9 | 200501-200509 |
| R10 | 9 | 200601-200609 |
| R11 | 8 | 200701-200708 |
| R12 | 8 | 200801-200808 |
| R13 | 9 | 200901-200909 |
| R14 | 9 | 201001-201009 |
| R15 | 13 | 201101-201113 |
| R16 | 10 | 201301-201310 |
| R17 | 12 | 201501-201512 |
| R18 | 7 | 201701-201707 |
| R19 | 11 | 201901-201911 |
| R20 | 10 | 202101-202110 |
|
Note 2.1: In round 3, the ID number system changed to a 4-digit year. |
||
In addition to retaining the previous ID code to permit linking across rounds, jobs reported at a previous interview retain the start date information from the previous round. For example, if a respondent began a job before the round 1 interview and continued it into the round 2 interview, the round 2 roster will contain the ID code assigned in round 1 and the round 1 start date information. However, all other information in the roster refers only to the time period since the round 1 interview date.
"Employer #01" is not necessarily employer number 9701, 9801, 199901, etc. The variables titled YEMP_UID.xx provide a crosswalk between the two systems of identification. For example, if the value of the round 2 variable YEMP_UID.01., 'YEMP, Employer 01 Unique ID (Ros Item),' is 9702, then the data regarding employer 9702 from the round 1 interview match with the information reported in the employer #01 variables in round 2.
Treatment of missing values. As mentioned previously, the NLSY97 interview collects information from the respondent on the start and stop dates of jobs and the beginning and ending dates of within-job gaps. These dates are transferred onto the individual's employment roster and additional questions within the survey are asked based on those data. For example, the length of time between jobs is calculated within the CAPI program using the job start and job stop dates, and the respondent is asked follow-up questions about the number of weeks spent actively searching for a job during each gap. If respondents report exact employment dates (e.g., no missing values are reported), the survey program proceeds without any adjustments.
If a respondent does not recall the exact month and day for an employment date, the missing information is imputed and stored in the individual's employment roster. This is done because many questions in the employment section cannot be asked if there is no month and day information, so an imputed month or day is used temporarily so that the section can be completed. For example, if the respondent does not know the start and stop days of the job, "1" is imputed for the start day and "28" for the stop day. Using these temporary days, the survey can ask questions such as those about job search activities during periods of unemployment. As in the case of jobs without missing information, the length of between-job gaps is calculated in the CAPI system using the information in the employer roster. When the respondent's answers include don't know or refuse, the length of between-job gaps is calculated from the imputed dates. Follow-up questions are then asked based on the imputed information.
When the data are being prepared for public release, the original missing values are inserted into the employer roster. At this point the employer roster reflects the actual responses given during the interview and not the temporary imputed values. Therefore, researchers can use the original answers in their analyses. However, they may wish to know what imputed values were substituted so that they can follow the correct question paths and understand the respondent's answers. A complete, detailed explanation of the imputation process is contained in Appendix 6 in the NLSY97 Codebook Supplement.
Event history data. The created event history variables (see Employers & Jobs) can be used in conjunction with the main file information about the respondent's employment. Like the main file variables, the event history variables use two systems of identification for a respondent's employers. First, the event history variables contained in the week-by-week status (e.g., EMP_STATUS_1997.01, where "01" indicates the first week of the year "97") and dual job (e.g., EMP_DUAL_2_1997.01) arrays use the unique ID numbers (UID) for each employer; to associate these employers with characteristic information collected during the interview, researchers must use the YEMP_UID.xx crosswalk variables. A second set of event history variables, those providing start and stop date information (e.g., EMP_START_WEEK_1997.01, EMP_END_WEEK_1997.01, where "01" indicates job #01), use the employer roster line numbers to identify the jobs. The number in the title of these variables refers to the same job as the variables in the main data set with the same number, so users can compare all information about job #02, for example, without any additional ID variables. However, to compare event history start and stop date information about job #02, for example, with information in the event history week-by-week status arrays, researchers must first use the YEMP_UID.xx crosswalk variables to identify the employer ID (9701-9707, 9801-9809, etc.) that matches job #02. See the example below to understand how this process works.
The employer roster: How the Event History data collection process works
The remainder of the section consists of a detailed example of how the Event History data collection process works.
Employer roster creation in round 1
Raw data collection
The round 1 survey asked for the names of all employers for whom the respondent had worked since age 14. Assume that a respondent named Emma reported delivering the Smalltown Press when she was 14, then switching companies and delivering the County Register, and finally working in her parents' business, Peel's Corner Store, at the time of the round 1 interview. For this example, the newspaper delivery jobs are assumed to be employee jobs and not freelance-type work. The survey then assigned a unique identification number (UID) in the order the jobs were reported: 9701 for the Smalltown Press, 9702 for the County Register, and 9703 for Peel's Store.
Roster creation and roster sort
After the UIDs were assigned, Emma reported the dates she started and stopped working for each employer. At this point, the survey program sorted the jobs according to stop date, so that the most recent employer was employer #01, the next most recent was employer #02, and so on. Therefore, Peel's Store (UID 9703) became job #01 on the roster, the County Register (UID 9702) was listed as job #02, and the Smalltown Press (UID 9701) was listed third. Key information about each employer, including the unique ID number and dates of employment, was organized in the employer roster. All of the information about Peel's Store is located in variables numbered #01 in the title, the County Register data are in variables numbered #02, and so on.
| Employer | UID | Round 1 Roster Line Number |
|---|---|---|
| Smalltown Press | 9701 | 03 |
| County Register | 9702 | 02 |
| Peel's Store | 9703 | 01 |
Roster use in the interview
Throughout the rest of the employment section, the employer line numbers remain constant, so that each variable containing, for example, the phrase "Job #03" or "Employer #03" refers to Emma's Smalltown Press job. Note that the Smalltown Press is not the third employer Emma reported at the beginning of the employment section of the interview. It became employer #03 during the roster sort because the other two jobs were more recent.
Roster creation in round 2
Data from previous interviews
The employer information was collected in a similar manner in subsequent rounds. Because data were available from the previous interview, they could be used in the construction of the round 2 roster. Before the survey was fielded, survey staff loaded information about each respondent into the interviewers' laptops. In Emma's case, part of this information would be the list of employers she reported in round 1.
Raw data collection
During the survey, respondents first provided information about employers who were current at the last interview date. Assume that Emma stated that she worked at Peel's Store for several months after the round 1 interview. Respondents next reported new employers since the last interview date in no particular order. Emma reported only one additional job, waiting tables at Steed's Diner after she turned 16. At this point UIDs were given to each employer. Because Peel's Store was previously reported, it already had a UID--9703--assigned during the last interview. Steed's Diner was a new employer in round 2, so it was given a UID of 9801.
Roster creation and roster sort
Emma then reported the date she stopped working at each job, and the roster was sorted according to these stop dates. At the round 2 interview, the diner job was more recent, so it was listed as job #01 on the roster, and the store became job #02. At this point, the roster contains information from multiple survey rounds. The UID and start date of the Peel's Store job are carried over from round 1, while the stop date of the store job and all the information about Steed's Diner comes from round 2. Because Emma had not worked for the Smalltown Press or the County Register since the round 1 interview, neither of those employers is listed on the round 2 roster.
| Employer | UID | Round 1 Roster Line Number | Round 2 Roster Line Number |
|---|---|---|---|
| Peel's Store | 9703 | 01 | 02 |
| Steed's Diner | 9801 | 01 |
Roster use in the interview
Just as in round 1, the employer line numbers remain the same for the rest of the interview. As Emma answered questions about Steed's Diner, her rate of pay, hours worked, etc., were recorded in the "Employer #01" questions. Peel's Store data were recorded in the "Employer #2" series.
Roster creation in round 3 and subsequent surveys
Data from previous interviews
This was collected as it was in round 2. Information reported in previous rounds, including the list of employers previously reported, was loaded into interviewers' laptops before the survey was fielded.
Raw data collection
During her round 3 interview, Emma reported her ongoing employment at Steed's Diner, where she had been working in round 2. In addition, she went back to work at the Smalltown Press for a 6-month period in between interviews. Both employers retained their original UID numbers, 9801 for the diner and 9701 for the newspaper, despite the break in Emma's employment at the latter.
Roster creation and roster sort
The roster is again sorted according to the stop date of each job. Since it is a current employer and does not yet have a stop date, Steed's Diner is listed as job #01 on the round 3 roster. The Smalltown Press becomes job #02 since Emma's employment there had stopped by the date of her round 3 interview. Previous jobs not reported in this round are not listed on this roster.
| Employer | UID | Round 2 Roster Line Number | Round 3 Roster Line Number |
|---|---|---|---|
| Steed's Diner | 9801 | 01 | 01 |
| Smalltown Press | 9701 | 02 |
Roster use in the interview
These employer line numbers are in place for the duration of the interview, just as in previous rounds. Information about her employment at the diner is recorded in "Employer #01" questions, while data about the newspaper are recorded in the "Employer #02" series.
Use of the employer roster in analysis
Emma's information, as organized in the employer rosters, can be used to examine the characteristics of her jobs at the date of each interview or over time. This example focuses primarily on the round 2 employer roster, but subsequent rounds also follow the same sequence for forming the employer roster.
As described above, Emma worked for Peel's Store and Steed's Diner during the period between the round 1 and round 2 interviews. Information about these employers was sorted and a roster constructed with the most recent employer appearing first. A researcher using these data would need to be aware of the impact of roster construction.
Because the roster is sorted and employers reported in different rounds may be mixed, variables with "Employer #01" in the title do not necessarily refer to employer number 9701, 9801, etc. The #01 refers solely to the order of the job as listed on the current year's roster. The unique identification numbers provide a crosswalk between the two systems of identification. The UIDs also allow users to link employers across survey rounds and to identify the round in which an employer was first reported.
For example, Emma's value for the round 2 variable R24761., "YEMP, Employer 02 Unique ID (Ros Item)," would be 9703--Peel's Store. The user can identify this as an ID assigned in round 1 because it starts with "97," and look at the round 1 UID variables (R05311.-R05317.) to match the employer. In Emma's case, the comparable variable for employer #01 in round 1 would have UID 9703. Therefore, the researcher knows that information about employer #01 in round 1 refers to the same job as variables about employer #02 in round 2. The variables from the two rounds can then be compared to determine if there were any changes in characteristics such as hours worked, rate of pay, occupation, etc.
The roster line numbers and UID variables in the event history data work in the same way. For example, a researcher might want to know Emma's employment status in the first and last week of 1998. In the first week of 1998 (variable EMP_STATUS_1998.01), Emma was working at her parents' store, so the status variable would have a value of 9703. Using this UID, researchers can link that job to all of the other information collected during the interview. For example, in the main round 2 data Peel's Store is job #02, according to variable YEMP_UID_1998.02 (R24761.). Similarly, for the final week of 1998 (variable EMP_STATUS_1998.01), when Emma was working at Steed's Diner, the status variable would have a value of 9801. The job with a UID of 9801 is employer #01 in round 2, so job characteristic data are contained in the employer #01 variables. The second set of event history variables, the start and stop dates of each job, uses the roster line numbers. For these variables, the number in the variable title refers to the same job as in the main data set. For example, the start and stop dates for Peel's Store in the event history data (variables EMP_START_WEEK_1998.02 and EMP_END_WEEK_1998.02) will also have #02 in the variable title.