
This section describes these three primary components of the NLSY79 codebook system and discusses the important types of information found within each. An additional codebook supplement exists for the Geocode data file.
Codebooks
The codebook is the principal element of the NLSY79 documentation system and contains information intended to be complete and self-explanatory for each variable in a data file. The software accompanying the NLSY79 data sets allows easy access to each variable's codebook information and permits the user to print a codebook extract for preselected variables.
Every variable is presented within the NLSY79 documentation as a block of information called a "codeblock." Each codeblock entry depicts the following important information:
- reference number
- variable title
- coding information
- frequency distribution
- location within the data file
- reference to the questionnaire item or source of the variable
- information on the derivation of created variables
Users will find that NLSY79 CAPI codeblocks present greater detail on each variable, including universe totals, universe skip patterns, and range of acceptable values information. Each of these terms is described more completely below. Codeblocks for many variables include special notes containing additional information designed to assist in the accurate use of data from that variable.
Codebooks are arranged in reference number order. As a general rule, raw questionnaire items appear first for a given survey year, followed by items from such instruments as the Information Sheet and Employer Supplement. Variables from the main body of the questionnaire are followed by created or constructed variables drawn from an external data source, such as the County & City Data Book.
Beginning with the 1993 CAPI surveys, questions relating to each job/employer, which were formerly located within the unique Employer Supplements, are merged with the main questionnaire items. A comparison of the reference number assignments used for the 1988 PAPI and 1993 CAPI variables appear in Tables 1 and provide users with a sample set of reference numbers. Users should note that not all survey year assignments will be ordered in precisely this manner.
| Description | 1988 PAPI Rnum | 1993 CAPI Rnum |
|---|---|---|
| All Raw, Edited and Created Variables | R25000.-R28927. | R41001.-R44308. |
| Questionnaire Items | R25000.-R27467. | R41001.-R43988. (including the Employer Supplement series) Note 1.1 |
| Information Sheet Items | R27469.-R27501. | R43989.-R44036. |
| Household Record | R27506.-R27609. | R44037.-R44126. |
| Employer Supplement (ES) Note 1.1 |
R27610.-R28254. | |
| Children's Record Form | R28255.-R28371. | R44127.-R44162. |
| Childhood Residence Calendar Note 1.2 |
R28372.-R28690. | |
| Created Variables | R28704.-R28729. | R44163.-R44205. |
| Supplemental Fertility File Variables | R28735.-R28811. | |
| Geocode Variables | R28825.-R28927. | R44206.-R44308. |
|
Note: PAPI refers to paper-and-pencil interviews which were conducted with the NLSY79 during 1979-92. CAPI or computer-assisted personal interviews began for the full NLSY79 cohort in 1993. Note 1.1: Beginning in 1993, variables from the employer supplement series are included within the raw questionnaire items. Note 1.2: The childhood residence retrospective was unique to 1988. |
||
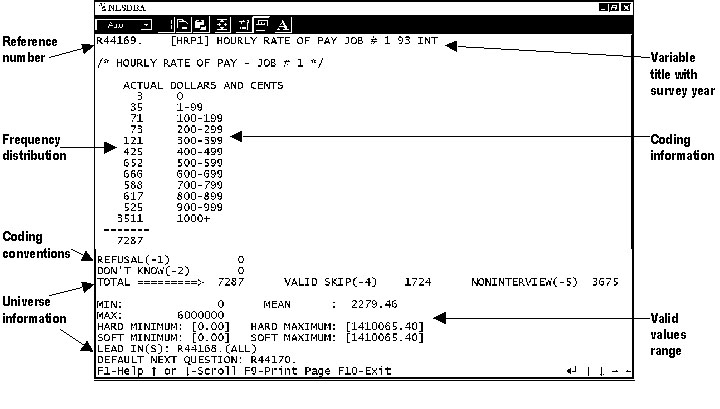
The following figures give users an example of codebook pages before (Figure 1) and after (Figure 2) CAPI implementation.
Figure 1. NLSY79 sample PAPI codeblock
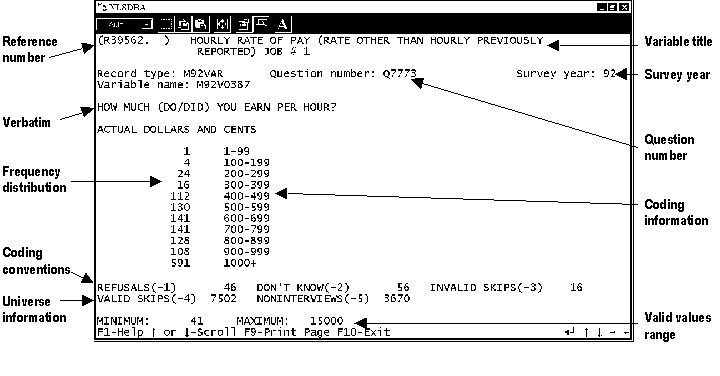
Figure 2. NLSY79 sample CAPI codeblock
Coding information
Each codeblock entry presents the set of legitimate codes that a variable may assume along with a text entry describing the codes.
Dichotomous variables
Dichotomous or yes/no variables that are uniformly coded "Yes" = 1, "No" = 0. Other dichotomous variables have frequently been reformulated to permit this convention to be followed.
Discrete variables
Discrete (categorical), as in the case of the categories in 'Activity Most of Survey Week CPS Item':
- WORKING
- WITH A JOB, NOT AT WORK
- LOOKING FOR WORK
- KEEPING HOUSE
- GOING TO SCHOOL
- UNABLE TO WORK
- OTHER
Continuous variables
Continuous (quantitative), as in the case of hourly rate of pay in the example above. These variables have continuous data but are presented in the codebook using a convenient frequency distribution. NLSY79 users will note that most valid data are positive numbers. Special cases are flagged by negative numbers in the NLSY79. See Appendix 13: Intro to CAPI Questionnaires and Codebooks in the NLSY79 Codebook Supplement for more detail on the handling of negative numbers in the data files. The following conventions have been used throughout the data:
- Noninterview -5
- Valid Skip -4
- Invalid Skip -3
- Don't Know -2
- Refusal -1
Important information: Coding information
Coding information for a given variable in the NLSY79 codeblock is:
- not necessarily consistent with the codes found within the questionnaire, and
- not necessarily consistent for the same variable across years. Use only the codebook coding information for analysis.
Frequency distribution
In the case of discrete (categorical) variables, frequency counts are normally shown in the first column to the left of the code categories. In the case of continuous (quantitative) variables, a distribution of the variable is presented using a convenient class interval. The format of these distributions varies.
Derivations
The decision rules employed in the creation of main file constructed variables have been included, whenever possible, in the codebook under the title "DERIVATIONS." This information enables researchers to determine whether available constructs are appropriate to their needs. In the case of the example NLSY79 variable in Figure 1, no derivation is shown because these variables are picked up directly from the interview schedule. Certain variables will contain a reference to an appendix for the decision rules that were used in creating the variable.
Questionnaire item
"Questionnaire item" is a generic term identifying the printed source of data for a given variable. A questionnaire item may be a question, a check item, or an interviewer's reference item appearing within one of the survey instruments.
The questionnaire location for NLSY79 entries appears either in parentheses or brackets directly after the reference number, for example R04434. (SO6D1314). The five questionnaire item numbering conventions used in the codebook are described in the Survey Instruments section (see especially Table 2).
Before the adoption of CAPI if an NLSY79 variable was not taken directly from one of the survey instruments, the questionnaire location contained an asterisk (*) in the codebook. The following categories of variables had no questionnaire numbers:
- assigned identification numbers for the respondent, child, or family unit;
- all derived or constructed variables;
- variables from the following special surveys: Profiles (ASVAB), the School Survey, and the Transcript Survey;
- variables found on constructed data files such as the Supplemental Fertility File (area of interest "Fertility and Relationship History/Created"); and
- variables drawn from an external data source such as those found on the Geocode files.
In CAPI years, survey staff assign a question name that is not used in the questionnaire. This name remains the same in subsequent rounds, so similar created variables can be easily located.
Section, deck, and question numbers have been somewhat arbitrarily assigned to the information and questions found in special survey instruments such as the Household Screener, Information Sheet, Children's Record Forms, Household Interview Forms, and the Employer Supplements. The section and deck numbers for these special survey items were numbered sequentially after the main survey items and their specific order varies each year. The exception to this is the assignment of the deck numbers for the Employer Supplements. Question numbering is discussed earlier in the Survey Instruments section (see especially Table 3).
Universe information
Universe information was attached to select 1979-92 variables. Beginning with the 1993 CAPI interviews, the amount of universe information was expanded to include:
Universe totals
Two totals are presented:
- the sum of the frequency counts for each coding category is presented below the individual codes; and
- the sum of the valid responses plus missing response counts of "refusals," "don't knows," and "invalid skips" can be found in the TOTAL==========> field. The number of respondents who legitimately did not respond to a question, that is, "valid skips (-4)" and "noninterviews (-5)," are also depicted.
Universe skip patterns
The following detailed universe information will enable researchers to easily trace the flow of respondents both backward and forward through various parts of the CAPI questionnaire items included in the codebook:
"Go to Reference # XXXXX.," appended to certain coding categories, indicates that respondents selecting that answer category were routed to the next question specified.
"Lead In(s) Reference # XXXXX." identifies the question or questions immediately preceding the codeblock question through which the universe of respondents was routed. Each lead-in reference number is followed by the relevant response value indicators, (Default), (ALL), [1:1], [1:6], and so forth. For example:
- R41000. (All) This means that all cases where R41000. is asked will branch to the current question. This does not imply all respondents are asked question R41000.
- R41000. (Default) This means that the default path of control from question R41000. is to branch to the current question, but there may be conditions under which a different path would be taken.
- R41000. [1:6] This means that whenever the response category for question R41000. takes on the values one to six inclusive, the next question is the current question record.
"Default Next Question" specifies the next question that all respondents of the current codeblock will be asked unless some other skip condition indicates otherwise.
Valid values range
Depicted below the frequency distribution is information relating to the range of valid values for that particular distribution. "MINIMUM" indicates the smallest recorded value exclusive of "NA" and "DK." "MAXIMUM" indicates the largest recorded value. The computer-assisted interview contains internal range checks that limit responses to those between predesignated values, alert interviewers to verify unusual values, and bolster the information provided by the traditional minimum and maximum fields (see, for example, Figure 2 above).
Maximum and Minimum fields
The MIN and MAX fields define the range, that is, the lower limit and the upper limit, of data values for a given question. A MAX of $156,359 on an income question, for example, means that this value was the highest value recorded.
Hardmax and Hardmin fields
Hard Maximum and Hard Minimum fields denote the highest and lowest values that were accepted by the CAPI program. A Hardmax of 500,000 and a Hardmin of 0 on an income question indicate that no values above $500,000 or values lower than zero (no income) can be accepted. Dates, such as month/day/year of the respondent's last interview [lintdate] and current interview [curdate], are used as Hardmin and Hardmax values in order to restrict responses to certain questions to values within that range. Responses outside this range must be entered by the interviewer in the comment field.
Softmax and Softmin fields
Softmax and Softmin fields cover ranges where an answer may exceed reasonable limits yet remain within the absolute limits and are acceptable after verification. A Softmax set to $80,000 on an income question will cause the machine to "beep" and a warning to appear on the screen. Interviewers are thus alerted that the value is unusual and the respondent's answer should be verified.
Restricted income values
Confidentiality issues restrict release of all income values. To insure respondent confidentiality, the values of income variables exceeding particular limits are truncated and the upper limits converted to a set maximum value.
- From 1979 through 1984, the upper limit on income variables was $75,000, and any amounts exceeding $75,000 were converted to $75,001
- Beginning in 1985, the upper limit on income amounts was increased to $100,000 due to inflation and the advancing age of the cohort, and amounts exceeding $100,000 were converted to $100,001
- Beginning in 1996, the top two percent of respondents with valid values were averaged and that average value replaced all values in the top range
Users should be aware of these changes in the income ceiling if they are carrying out longitudinal analyses with these data. Upward trends in mean income statistics may reflect this change in the ceiling value. More information about truncation is available in the Income section.
Restricted asset values
Confidentiality issues also restrict release of all asset values. To insure respondent confidentiality, the values of asset variables exceeding particular limits are truncated and the upper limits converted to a set maximum value. The asset amounts have different upper limits, and the types of variables and limits for those variables are as follows:
- Starting in 1985 all mortgage, market value of residential property, debt on residential property, miscellaneous debt and total market value of assets worth more than $150,000 were converted to $150,001; the market value and debt on a farm or business and savings that was worth more than $500,000 was converted to $500,001; the market value and debt on vehicles that was more than $30,000 was converted to $30,001
- Beginning in 1989, the amounts exceeding the upper limits mentioned above were assigned the average value of all values exceeding the limits, in an effort to more accurately reflect the true range of income and asset values
- Beginning in 1996, the top two percent of respondents with valid values were averaged and that average value replaced all values in the top range
Users should be aware of these changes in the asset ceiling if they are carrying out longitudinal analyses with these data. Upward trends in mean asset statistics may reflect this change in the ceiling value. More information about truncation is available in the "Assets" section of this guide.
Verbatim
Generally during the PAPI years, when a NLSY79 variable was taken directly from the questionnaire, the verbatim of the question appeared beneath the variable title. If a question is the source for more than one variable, the first variable contains the verbatim while subsequent variables prompt the user to refer back to the variable containing the verbatim. The following verbatim responses appear for reference numbers R03194. and R03195. and demonstrate this convention.
- R03194. 'In Which Months of 1979 Did You (or Your Husband/Wife) Receive Supplemental Security Income? January 80 INT'
- R03195. 'See R (3194.) February'
Codebook supplements and other technical documentation
The Other Documentation section of the website includes several items that provide additional information about the NLSY79 survey. There are two NLSY79 codebook supplements. The first supplement, the NLSY79 Codebook Supplement, contains a series of attachments and appendices, variable creation procedures, supplementary coding categories, and derivations for selected variables on the main NLSY79 data files. Information provided within this document is not available in the NLSY79 codebooks, nor will it be found on the documentation files on the NLSY79 data sets. The other supplement contains comparable information specific to the NLSY79 Geocode data files. The Technical Sampling Report describes the selection of the NLSY79 sample and provides additional statistical information. Finally, the School & Transcript Surveys Documentation provides technical information about those special data collections.
Error updates
Prior to working with an NLSY79 data file, users should make every effort to acquire information on current data or documentation errors. A variety of methods are used to notify users of errors in the data files or documentation and to provide those persons who acquired an NLSY79 data set directly from the Center for Human Resource Research with corrected information.
When data errors are discovered within the data file, the correction is made and the date file is updated. These updated files then become the default files on NLS Investigator. NLSY79 Errata notices can be found in "Other Documentation" section.